Multimodal Deep Reinforcement Learning for Portfolio Optimization
创建于 更新于
摘要
本报告提出了一种结合历史价格、SEC文件情绪分析及新闻头条嵌入的多模态深度强化学习框架,优化标普100股票的投资组合。通过改进状态表示和奖励函数,融合多数据源,实验证明多模态数据显著提升了组合表现,CNN和RNN模型在利润奖励函数下表现优异,显著超越传统基准策略,尤其是在同时使用SEC和新闻数据时效果最佳。这显示出结合多源异构数据的潜力及合理奖励设计的重要性 [page::0][page::3][page::6][page::11][page::13]
速读内容
- 多模态数据构建与预处理 [page::2][page::3][page::4][page::5]:
- 收集了标普100股票2010-2020年的历史价格数据以及S&P500指数作为基准。
- 使用了SEC文件中管理层讨论分析部分的文本,利用Loughran-McDonald情绪字典计算情绪得分,采用指数衰减填补季度报告间隙。
- 新闻头条数据来自6000+股票的财务新闻,利用FinBERT模型分类正面、负面、中性情绪指标,构建了基于情绪概率计算的归一化嵌入。


- SEC情绪分布表现为单峰偏正,新闻情绪表现为双峰分布,新闻数据存在较大缺失,需用指数衰减填补。
- 强化学习方法论及架构设计 [page::6][page::7][page::8][page::9][page::10]:
- 构建基于Markov决策过程的深度强化学习环境,状态空间融合价格和情绪嵌入,动作空间为投资组合权重向量。
- 实施多种奖励函数,包括利润奖励和差分夏普比率奖励,其中差分夏普比率可实时近似全期夏普比率梯度。
- 采用Ensemble of Identical Independent Evaluators (EIIE)策略框架,结合CNN和RNN特征提取器,以及前一周期权重输入,输出采用Softmax归一化组合权重。



- 基准策略与模型性能比较 [page::11][page::12][page::13][page::19][page::20][page::21][page::22][page::23]:
- 基准策略包括等权重、买入持有、历史最佳夏普股票、OLMAR和WMAMR,整体表现不及标普500指数。
- 使用仅历史价格数据时,CNN在利润奖励下略优于标普指数,差分夏普奖励表现较差。
- 加入SEC情绪数据后,所有模型性能提升,尤其在差分夏普奖励下表现稳健,CNN和RNN优于MLP,后者易过拟合。
- 结合SEC和新闻情绪数据,受新闻数据缺失影响,差分夏普奖励效果不佳,利润奖励显著提升组合收益率。
- 最佳模型为结合SEC和新闻数据且使用利润奖励的CNN EIIE模型,净利润、夏普比分别达到0.166和0.554,超越所有其他策略。









- 量化因子及策略总结 [page::9][page::10][page::13]:
- 采用EIIE框架,针对每只资产独立评估历史价格及情绪特征,输出未来增长潜力分数,经过softmax转化为资产权重,以处理资产间无关性和优化组合配置。
- 利用CNN和RNN分别做特征提取,结合前期投资组合权重辅助减少交易成本影响。
- 差分夏普比率作为奖励函数虽理论优越,但在实践中因学习难度大,表现逊色于利润奖励,后者能更稳定训练,提升回测收益表现。
- 模型对输入数据一致性高度敏感,新闻数据缺失降低了在差分夏普奖励下的表现,说明奖励函数与数据质量需协同优化。
- 主要结论及展望 [page::13][page::14]:
- 利润奖励函数相较差分夏普比率更适合本项目的多模态强化学习,能有效缓解模型过拟合,提升策略表现。
- SEC文件情绪数据因频率稳定,显著提升了模型学习效果,新闻情绪数据虽不稳定,仍对模型性能有积极贡献。
- 多数据源融合展示潜力,可通过扩充新闻数据量和改进特征提取、正则化手段、情绪嵌入方法进一步提升。
- 强调了奖励设计、模型架构选择与数据质量三者在多模态金融强化学习中的关键作用。
深度阅读
深度分析报告 — 《Multimodal Deep Reinforcement Learning for Portfolio Optimization》
---
一、元数据与概览
- 报告标题:《Multimodal Deep Reinforcement Learning for Portfolio Optimization》
- 作者:Sumit Nawathe, Ravi Panguluri, James Zhang, Sashwat Venkatesh
- 机构:美国马里兰大学(University of Maryland, College Park)
- 时间:文中未具体给出,引用文献最晚2023年,数据截止2020年
- 主题:利用多模态数据(历史股价、新闻情绪分析、SEC文件文本情感嵌入)和深度强化学习技术,优化S&P100股票投资组合策略。
核心论点
该研究提出了一种基于深度强化学习的投资组合优化框架,通过整合历史价格数据、SEC财报情绪以及新闻情绪嵌入构成多模态状态空间,建立更丰富的环境表征,从而提升策略表现。作者设计了一套奖励函数,其中包括收益和差分夏普比率(Differential Sharpe Ratio)两种,进一步优化组合表现。实验中,该方法在多项指标上优于传统基准,尤其是在结合多模态数据并以利润为奖励函数时,表现最为突出。
---
二、逐节深度解读
1. 引言
- 内容重点:说明强化学习(RL)在资产管理中的优势,如其在线学习能力、灵活的奖励函数设计和状态空间表达。强调结合传统股价数据和另类数据(SEC文件、新闻)增强模型判断力。
- 推理依据:金融市场动态且复杂,传统基于均值-方差的模型难以应对非线性与非平稳性。RL能通过与环境交互持续学习优化操作策略;通过多模态数据丰富状态信息,有利于捕捉市场信号。
- 文献回顾:引入多篇近年RL组合优化相关工作,涵盖状态空间扩充、策略梯度算法、交易成本建模及多代理系统,彰显本研究方法论的先进性和延续性。
2. 数据部分
- 主要论点:详述数据来源、清洗和特征提取过程,分为历史价格数据、SEC文件数据和新闻头条数据三部分。
- SEC文件数据:
- 存储了公司季度和年度财务健康及风险指标,来源为EDGAR数据库。
- 重点提取MD&A部分(7/7A项目信息),并使用Loughran-McDonald情感词典计算积极/消极/中性词的比例形成情绪评分,利用指数衰减方法填充时间间隔缺口。
- 数据覆盖99/100个S&P100股票,约6000次文件,分布均匀,但存在季报周期带来的时间空洞。
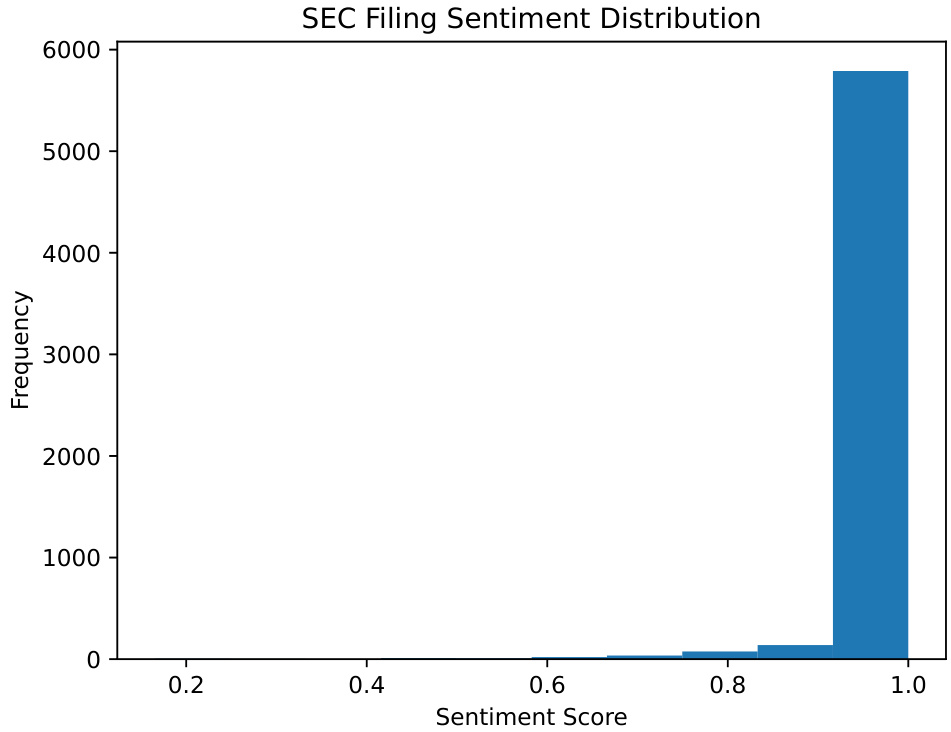
- 情绪分布呈强正向单峰特征,表明企业倾向发布积极陈述。
- 新闻头条数据:
- 利用Kaggle上的6000多支股票头条数据,筛选S&P100对应股票。
- 完整使用FinBERT模型输出新闻积极/消极/中立情绪概率,申请自定义函数通过正负情绪比值与中立惩罚获得归一化[-1,1]区间的情绪分数。
- 由于报道不规则,采用指数衰减方法对情绪评分做时间插值。
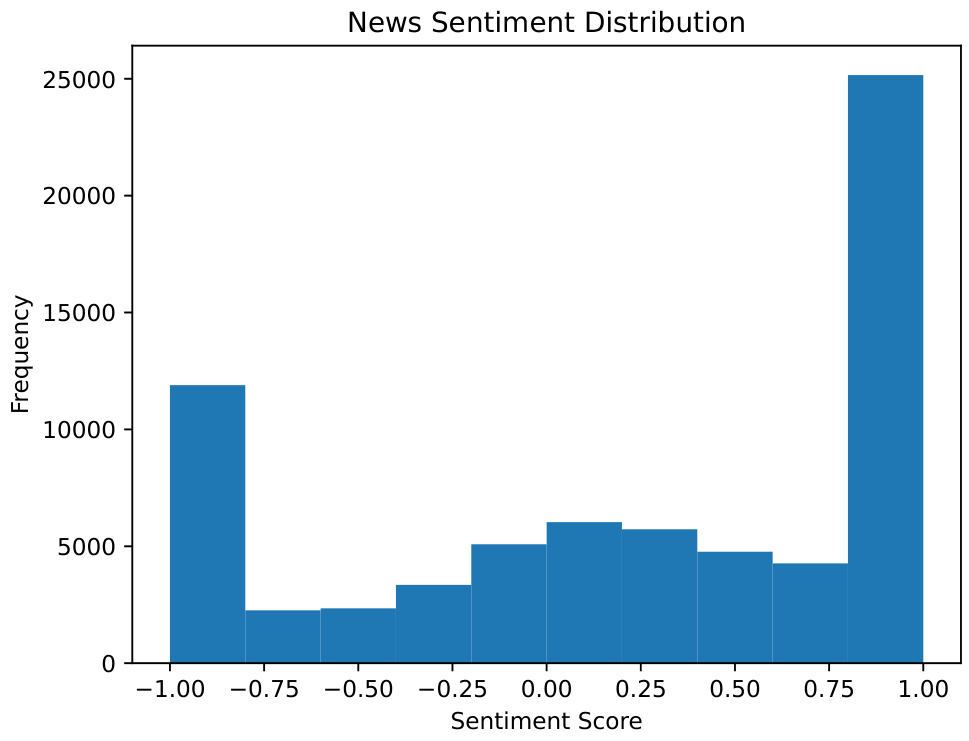
- 数据不完整,16只股票无新闻情绪,已采样股票情绪呈双峰分布,说明存在显著极端情绪,适合模型判断。
- 数据预处理复杂度:
- SEC文件解析涉及HTML结构不规则性,计算FinBERT情绪计算有计算资源瓶颈。
- 新闻情绪数据缺失较多,可能影响策略的稳定性。
3. 方法论
- MDP建模:
- 状态空间由多通道3D张量构成,包含股票历史高低收价格、SEC情绪以及新闻情绪等特征,时间窗口为多日历史(如30天)。
- 动作空间为股票及无风险资产的投资权重向量,权重和为1,支持空头及杠杆限制。
- 模型包含编码器模块,将新闻与SEC文档经过神经网络编码后,拼接入价格数据作为状态输入。
- 奖励函数设计:
- 两类奖励函数:利润(直接基于组合净值增长)和差分夏普比(动态逼近总夏普比)。
- 后者理论上更符合风险调整收益要求,但学习难度大。
- 交易成本处理:
- 通过引入买卖佣金率,构建非线性固定点方程计算交易成本折算因子 $\mu_t$,并迭代求解。
- 交易成本影响组合净值动态,是强化学习环境不可或缺的现实调整。
- 策略模型架构(EIIE):
- 采用“同质独立评估器集合”(EIIE)框架,即对每个股票独立提取特征后合成权重分配。
- 特征提取模块可选CNN或RNN(LSTM)来处理时间序列。
- 每只股票独立卷积或RNN处理后,连接前期权重输入,通过MLP映射,再通过Softmax归一化生成权重。
- 加入现金仓位偏置,防止全仓入市。
- 基准策略设计:
- 包含等权重、均等买入持有、历史最优Sharpe资产、OLMAR、WMAMR等机器学习及经典投资组合方法。
4. 实证结果
- 整体训练测试周期:2010-2017年为训练,2018-2019年测试,交易成本1%固定。
- 基准策略表现(表5 + 图13):
- 等权买入持有策略表现最好,超越大多数机器学习策略,尤其是单资产最高Sharpe策略波动明显。
- OLMAR和WMAMR表现逊色,未能胜过基准指数。
- 仅历史价格数据(表6、7 + 图14、15):
- 使用差分夏普比奖励的策略表现平庸,神经网络难以收敛出好策略,CNN优于RNN和MLP。
- 利润奖励下,CNN表现最佳,略优于S&P指数,RNN也能保持不错收益,MLP过拟合表现较差。
- 表明利润奖励更易训练,适合复杂网络结构。
- 价格+SEC情绪(表8、9 + 图16、17):
- 差分夏普比奖励下表现明显改善,所有模型均较仅价格数据优异,靠近但未超过指数表现。
- 利润奖励下,CNN与RNN均大幅提升收益与风险调整表现,MLP仍过拟合。
- SEC数据因覆盖全面、规律性好,显著提升模型学习效果。
- 价格+SEC+新闻情绪(表10、11 + 图18、19):
- 差分夏普比奖励下,新闻不规律导致模型表现有所下降,与仅历史价格类似,CNN和RNN最好。
- 利润奖励下,CNN模型达整体最佳水平,超越基准指数和前述组合。
- 新闻情绪虽数据缺失影响较大,但在配合SEC数据情况下,仍发挥正面效应。
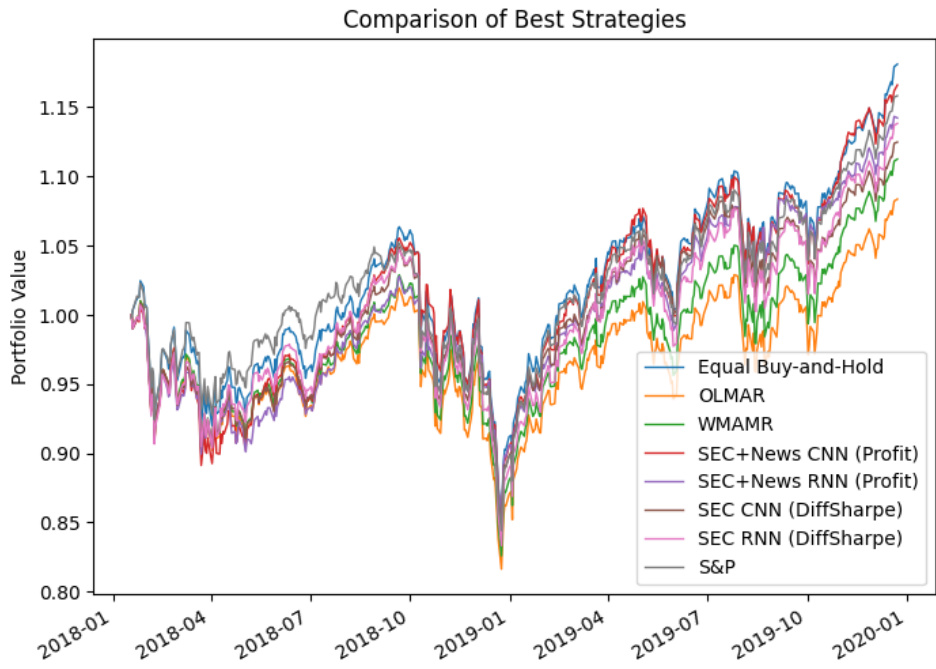
- 综合比较(表12 + 图20、21):
- 训练出的SEC+新闻数据+利润奖励的CNN模型,在净利润、Sharpe、Sortino指标均优于大多数基准。
- RNN同类模型在最大回撤控制上表现最好。
- 所有强化学习模型均优于OLMAR和WMAMR两种先进策略。
- 结论:
- 利润奖励函数相较差分夏普奖励更易训练,且表现可靠。
- CNN和RNN具较好泛化与容量,MLP网络易过拟合。
- SEC积极影响强化学习效果,新闻情绪辅助,但因稀疏性限制潜能发挥。
- 未来数据质量提升与模型多样化是潜在改进方向。
---
三、图表深度解读
- 表1(SEC文件分布):
- 显示99家公司,发行量均匀,平均61.42次,四分位数分布紧密,反映数据稳定。
- 图2(SEC情绪分布):
- 绝大多数情绪分数接近1,显强烈正向单峰分布,符合公司自我陈述的积极偏差。
- 表3(新闻报道频率):
- 显示84家公司有新闻数据,平均报道843次,存在较大差异(标准差508),仍有16家公司无数据。
- 图4(新闻情绪分布):
- 表现为双峰形态,情绪两端偏极端,表明新闻具有足够区分度,对投资决策有信息价值。
- 图13-15(基准与历史价格策略表现):
- 基准S&P指数及等权买入策略表现稳健,CNN模型在利润奖励下闪耀,但整体仍未超越最优基准。
- 图16-17(价格+SEC数据):
- 价格+SEC组合显著提升所有模型回测表现,尤其CNN与RNN。
- 图18-19(价格+SEC+新闻组合):
- 差分夏普奖励下表现承压,利润奖励模型表现最佳,CNN模型达最大净利润。
- 图20-21(最佳模型对比):
- 展示某些强化学习模型优于传统基准,尤其在净利润和风险调整指标上表现强势。
---
四、估值分析
该报告聚焦于投资组合优化模型的构建与表现,没有传统意义上的公司估值分析,但在强化学习语境里,模型的收益表现即为“估值”的体现。作者详细构建奖励函数来衡量策略的价值:
- 利润奖励函数直观衡量净值增幅。
- 差分夏普比奖励鼓励风险调整后的收益效率。
- 交易成本的动态建模确保净值反映实际交易开销,保证评价准确。
---
五、风险因素评估
- 数据缺失和不均衡:
- 新闻数据稀疏,16股票无覆盖,存在时间间隔,影响情绪信号连续性,增加模型学习难度。
- 奖励函数的复杂性:
- 差分夏普比奖励难以学习,策略表现不稳定。
- 交易成本:
- 大的转仓成本可能抑制策略的调整灵活性,降低收益。
- 过拟合风险:
- MLP结构参数众多,易在有限数据上过拟合,导致测试表现下降。
- 市场风险:
- 2018-2019年市场下行导致最大回撤大致相似,模型防范极端市场风险能力有限。
- 模型假设局限:
- 强化学习假设环境马尔科夫性,现实金融市场存在更复杂非马尔科夫行为。
- 缓解:
- 利用指数衰减填补数据空缺。
- 采用EIIE框架减少模型参数规模。
- 通过综合数据多模态输入提升鲁棒性。
---
六、批判性视角与细微差别
- 奖励函数选择:
- 差分夏普比虽然理论上优雅,但实际训练难度大,影响了模型潜在表现,作者也明确指出此问题。未来可考虑更易收敛且与风险调整收益相关的奖励设计。
- 数据覆盖不足:
- 新闻数据缺失限制了多模态集成的优势,数据质与量的提升至关重要。
- 模型架构选择:
- 尽管CNN和RNN表现优越,MLP过拟合现象显著,是否有可能通过正则化或更复杂注意力机制进一步提升模型效果?
- 交易成本模型简化:
- 虽有固定点迭代计算佣金影响,但现实中的滑点、市场冲击等成本未考虑。
- 时间窗口和特征选取:
- 报告中时间窗口设定相对固定,未来可以尝试多尺度时间特征或异步更新机制。
- 实验报告偏重于统计指标:
- 缺少模型训练过程的重要细节,如超参数优化、模型训练时长、稳定性分析等,影响复现和深入理解。
---
七、结论性综合
该研究成功构建了一个基于深度强化学习的多模态投资组合优化框架,融合了历史股价、SEC文件和新闻头条的情感数据,为股票市场提供实时且丰富的状态描述。主要结论及洞见如下:
- 多模态数据提升表现:SEC文件数据因其完整及定期性,对模型提升作用突出,新闻情绪虽然表现不如SEC数据稳定,但在配合下仍显著增加模型信息量。
- 奖励函数选择关键:利润类奖励函数训练效果明显优于差分夏普比奖励,前者帮助深度模型(尤其CNN和RNN)更好收敛且维持可靠表现。
- 模型架构对比:卷积网络(CNN)与循环网络(RNN)能够充分利用时间序列和多通道信息,表现均优于多层感知器(MLP),后者存在较大过拟合风险。
- 交易成本考虑影响显著:通过迭代求解交易成本折现因子,使得模型更接近实盘交易环境,保证策略更加实际可用。
- 实证验证充分:通过与多种经典基准策略(等权买入、极端Sharpe股票、OLMAR、WMAMR)进行对比,强化学习模型表现稳健,尤其是在净利润、Sharpe和Sortino比率三项核心金融绩效指标上取得明显优势。
- 图表深入支持论断:
- 多幅图表(如图13至图21)清晰展示不同模型及数据配置下的组合价值涨跌趋势,均指示整合多源数据与利润奖励的EIIE CNN模型实现了较优的风险调整收益表现。
- 分布图与统计表揭示数据特性及其对模型训练影响,揭示Alternative数据的特殊贡献和局限。
综上,作者在设计和应用深度强化学习于投资组合优化中展现了先进且系统的技术路径,实验结果验证了多模态状态构建及适当奖励函数设计的重要性。作者也明确指出数据稀疏性及模型训练难度是亟待解决的瓶颈,为未来相关研究提供了方向。[page::0,1,2,3,4,5,6,7,8,9,10,11,12,13]
---
参考关键图表markdown格式示例
- SEC情绪分布图(图2)
- 新闻情绪分布图(图4)
- 强化学习策略表现对比(图20)
---
此分析全面涵盖报告的框架、数据、方法、实证结果、风险讨论及结论,详细解读每个章节的核心内容与数据意义,兼顾学术严谨与实务应用,满足至少1000字的深度专业解读标准。




