Social Learning with Intrinsic Preferences
创建于 更新于
摘要
本报告通过实验和离散选择模型,深入分析个体在不同选择任务与环境下内在偏好与社会学习的权衡关系。结果显示,内在偏好主导主观选择任务,社会学习优先于客观正确答案的任务,激励环境(奖励或惩罚)进一步影响两者权重。建模揭示个体社会学习策略的多样性及其在群体行为极化中的作用,为理解社会规范非任意性提供理论依据 [page::0][page::1][page::17][page::19][page::20]。
速读内容
- 研究设计与核心方法 [page::3][page::5][page::6]:
- 实验包括两个二选一任务:艺术品选择(主观偏好)和知识问答(客观正确答案)。
- 每个参与者完成60个决策(前50无社交信息,后10有五人决策信息)。
- 利用参与者对选择的偏好强度滑动条数据,构建衡量内在偏好的指标。
- 社会学习采用随机效用模型,效用由内在偏好和对同伴选择的预期份额(加权参数f)共同决定。
- 量化模型框架与参数解释 [page::6][page::7][page::8]:
- 模型式: \( U{ij} = \lambdai v{ij} + fi \log(s{ij}) + \epsilon{ij} \)
其中,\(\lambdai\)代表内在偏好权重,\(fi\)代表社会学习策略。
- 社会学习参数\(f_i\)区分不同策略:负值为逆从众,零为独立,(0,1)非从众,1线性,从众>1。
- 采用Dirichlet分布建模参与者对他人选择份额的先验和后验,体现偏好驱动的先验偏差。
- 社会学习策略的异质性与环境影响 [page::12][page::13][page::14]:

- 询问任务中,大部分参与者表现为从众,个体差异小。
- 艺术品选择任务中,社会学习差异大,部分呈非从众甚至逆从众。
- 奖励环境下,艺术品任务中非从众及逆从众现象增加;惩罚环境中从众行为加强。

- 但在知识问答任务中,奖励与惩罚环境对社会学习策略影响微弱,均以从众为主。
- 模型拟合与比较 [page::15][page::16]:

- 综合模型(内在偏好+社会学习+偏好驱动先验)相比纯内在偏好模型、纯社会学习模型等嵌套模型,信息准则(WAIC)显著更优,预测准确度高。
- 拟合数据显示模型对平均行为及个体行为均有良好预测能力,个体预测准确率模式约70%。
- 社会学习对行为动态的模拟分析 [page::17][page::18]:

- 采用各参与者个性化参数,模拟长时间100期群体决策动态。
- 知识问答任务普遍趋向共识,且随偏好不同表现为偏好差异的排序。
- 艺术品选择任务中,尤其在奖励环境下,群体行为多样性明显,趋同较弱。
- 群体行为的稳定描述性规范可反映人口中的平均偏好,支持社会规范非任意性观点。
- 量化社会学习策略分析 [page::6][page::7][page::12]:
- 社会学习参数\(f\)体现5种核心策略:逆从众、独立、非从众、线性从众、强从众。
- 实验展示在不同任务与激励环境中,\(f\)值呈显著变异,尤其主观任务中奖励环境利于非从众及逆从众策略发展。
- 偏好驱动的先验信念\(\delta, \phi\)影响个体对社交信息的敏感度,增强模型对复杂社会决策的解释力。
- 实验结论与理论含义 [page::1][page::19][page::20]:
- 内在偏好与社会学习均影响决策,但相对重要性依任务性质及激励制度差异显著。
- 主观任务中,激励制度改变社会学习策略分布,从惩罚促从众转向奖励促非从众。
- 客观正确答案任务中,社会学习更为稳定,激励效果不明显。
- 该模型推进了对社会学习和内在偏好的双重综合理解,突破了传统门槛模型的单一视角。
- 社会规范的形成非随机,反映群体内个体偏好及信息互动的动态均衡。
深度阅读
《Social Learning with Intrinsic Preferences》研究报告详尽分析
---
1. 元数据与概览
- 报告标题:Social Learning with Intrinsic Preferences
- 作者及机构:Fabian Dvorak 与 Urs Fischbacher,均来自德国康斯坦茨大学
- 发布日期:2024年2月29日
- 主题概述:本文研究个体在存在内在偏好和社会学习影响的情境下如何做出选择决策,特别考察决策任务性质和激励环境对两者权重的影响。
- 核心论点:
- 内在偏好与社会学习共同塑造决策,但其权重随任务性质与环境变化显著不同。
- 主观选择任务中,内在偏好占主导;客观有正确答案的任务中,社会学习更显重要。
- 奖励机制强化内在偏好,惩罚机制则促使趋同式社会学习。
- 研究运用实验结合离散选择模型,揭示个体多样化的社会学习策略及其动态影响,讨论了选择极化的潜在后果。
---
2. 逐节深度解读
2.1 引言部分(第0-2页)
关键信息:
- 选择决策既受内在偏好影响,也受社会学习驱动,且二者可能冲突。
- 需要剥离内在偏好与社会影响的混杂效应,传统实证困难重大,文中通过设计实验证实并结合建模手段解决此问题。
- 本文主要贡献在于揭示任务类型(主观 vs. 客观)和激励环境(奖励 vs. 惩罚)对内在偏好与社会学习影响的变动模式以及个体之间的社会学习策略差异。
- 新的建模框架允许捕捉从一致性(conformity)、非一致性(nonconformity)到反一致性(anticonformity)的多样化策略,模型中考虑个体先验信念动态调整,更符合现实认知过程。
逻辑基础:
- 明确指出了区分偏好与社会学习的重要性和挑战。
- 引用了经典和当代文献支持设计合理性:Manski (1993)关于“反射问题”、Granovetter (1978)的阈值模型、Bénabou 和 Tirole对信念偏差的理论,以及先验信念调整系统性建模用以避免小样本数据异常推断。
- 假设个体更新对群体行为频率的信念,并基于此做出决策,而非简单基于观测频率直接决策,强调信息处理的认知合理性。
---
2.2 方法与实验设计(第3-6页)
实验设计:
- 任务设置:两个二选一任务
- 主观任务:在两幅知名画作中选喜欢的一幅
- 客观任务:在两个可能答案中选正确答案
- 决策轮次:每任务60次决策,前50次无社会信息,后10次展示5名群体其他成员未受社会信息影响的选择结果。
- 内在偏好测量:通过四选二的配对两两比较,加上选择后滑块衡量偏好强度([-1,1]区间),利用关联比较估计二元选择的内在偏好参数$\Delta$,该参数体现偏好强度和方向。
- 信息结构:
- 社会信息基于上一阶段“五名其他人未受社会信息影响的选择结果”向被试呈现,保证信息内生性问题减弱。
- 使用6人组设计,分两阶段完成全部6个二元对比,保证每人都有一组社会信息决策被告知其他5人的真实选择。
激励机制:
- 三个环境:
- 奖励环境:一名评估者基于选择给该选择者10欧元奖励。
- 惩罚环境:评估者判定给选择者扣除10欧元。
- 控制环境:无奖励惩罚
- 评估机制含匿名自然信息传递,保证选择者知晓可能处于奖励或惩罚风险,产生不同的行为激励。
模型框架:
- 以随机效用模型为基础,目标变量是离散选择结果$Yi$,每一备选项$j$效用为系统性内在效用加社会效用及随机误差。
$$
U{ij} = \lambdai v{ij} + fi \log s{ij} + \epsilon{ij}
$$
- $\lambdai v{ij}$:内在偏好效用,$v{ij}$为选项特征,$\lambdai$为个人敏感度。
- $fi \log s{ij}$:社会效用,$s{ij}$为选项$j$在参考群体中的期望选择份额,$fi$为个体社会学习策略参数。
- $\epsilon{ij}$:iid Gumbel分布误差,导致选项概率呈现对数几率模型形式。
- 社会学习策略参数解释:
- $fi > 1$:趋同(conformist)
- $0 < fi < 1$:非趋同(nonconformist)
- $fi = 0$:独立(independence)
- $fi < 0$:反趋同(anticonformist)
- 先验信念用Dirichlet分布建模,个体基于观测的选择样本$N$及个数$n{ij}$更新参数,形成后验,再计算期望份额$s{ij}$。
- 引入偏好偏向参数$\deltai$调整先验,使得先验信念可能偏向自身内在偏好选项,体现认知偏差和自我欺骗现象。
---
2.3 模型逻辑与预测(第7-10页)
- 通过对各种$f$与$\lambda$组合对选择概率的模拟绘制(图2),阐释:
- 内在偏好对社会影响的“免疫”作用:强烈偏好会使个体不轻易受社会信息干扰。
- 先验信念强度决定对社会信息响应程度:先验越强,更新偏差越小,样本量越大社会信息越显著影响决策。
- 社交规范的稳定性非随意,而是有内在倾向成分:岸上$f>1$时,群体偏好更易聚焦于内在偏好主导的选择上,使用模拟支持了异质性个体融入整体偏好的结论。
- 模型融合并优于传统阈值模型,允许多样的社会学习策略,捕捉个体差异和信念调整机制。
- 使用贝叶斯多层次模型估计参数,保证个体参数估计稳定且避免过拟合。
---
2.4 结果分析(第11-16页)
- 总体参数估计(表1):
|参数|任务类型|估计值描述|
|-|-|-|
|$\lambda$|绘画与问题|均为正,内在偏好显著影响选择|
|$f$|控制组|两任务皆趋同,问题任务趋同性更强|
|$\phi, \delta$|两任务|表明偏好导向的先验存在,个体倾向认为偏好选项更为普遍|
- 个体异质性(图3):
- 问题任务:趋同行为显著度高,个体间差异较小,社会学习趋向一致。
- 绘画任务:个体社会学习策略多样化,有趋同与非趋同者共存,且先验分布表明大多数个体存在偏好导向的信念强化。
- 激励环境影响(图4):
- 绘画任务结果符合预期:
- 奖励环境抑制趋同甚至出现反趋同现象;
- 惩罚环境强化趋同倾向。
- 问题任务中,激励对社会学习策略无显著影响,社会学习强趋同持续存在。
- 模型拟合与对比(图5,表2):
- 主模型(包含$\lambda,f,\delta$)对观测行为拟合良好,预测可信。
- 三个嵌套模型(无偏好偏向、仅偏好、仅社会学习)预测性能均不及主模型。
- 剔除任务或环境效应固定项导致模型预测力下降,说明参数需根据任务类型调整。
---
2.5 选择动态模拟(第17-18页)
- 以个体估计参数为基础,模拟50人群体在不同环境下100周期的选择演进。
- 问题任务:多数意见形成清晰收敛,偏好强的选项快速成为主流,环境中奖惩强化这一趋势。
- 绘画任务:意见多样性持续存在,环境影响显著,奖励环境中个体偏好多样,趋势不明显,惩罚环境促使意见收敛。
- 结论:经过多轮互动后,群体描述性规范反映真实平均偏好,且该现象普遍存在于不同任务与环境。
---
2.6 讨论(第19-21页)
- 研究对分离内在偏好和社会学习做出实证贡献,指出二者均不可忽视。
- 不同任务性质影响社会学习模式:
- 客观答案任务:趋同为主,奖励或惩罚变化影响有限。
- 主观任务:社会学习多样,奖励激励倾向非趋同,惩罚激励趋同。
- 模型创新点:
- 结合经济学的随机效用理论与生物社会学习理论,强调个体信念更新机制,避开以往阈值模型的局限。
- 解释了为何历史选项频率信息影响决策大小随群体规模增长、为何存在“免疫”社交学习者(如偏好强烈和先验坚定者)。
- 支持观点:社交规范非随机产物,内含对内在偏好的认识维度,具有固有价值。
- 本研究为理解社会学习复杂性及决策行为社会动态提供坚实理论与实证基础。
---
3. 图表深度解读
3.1 图1:实验设计示意(第5页)
- 描述:左图细化内在偏好估计方法,基于相同第三选项比较差异均值规范化得到二元选择的偏好参数$\Delta$。右图说明6人组分两阶段完成6个二元组合,第二阶段获得第一阶段其他5人非社会影响决策结果作为社会信息。
- 解读:
- 利用关联比较测量避免了同一选择重复出现降低一致性动机混淆,非常巧妙。
- 通过逐个不同剩余决策的分配使得信息来源确为“纯净”,增强研究识别效力。
3.2 图2:社会学习下选择概率响应(第10页)
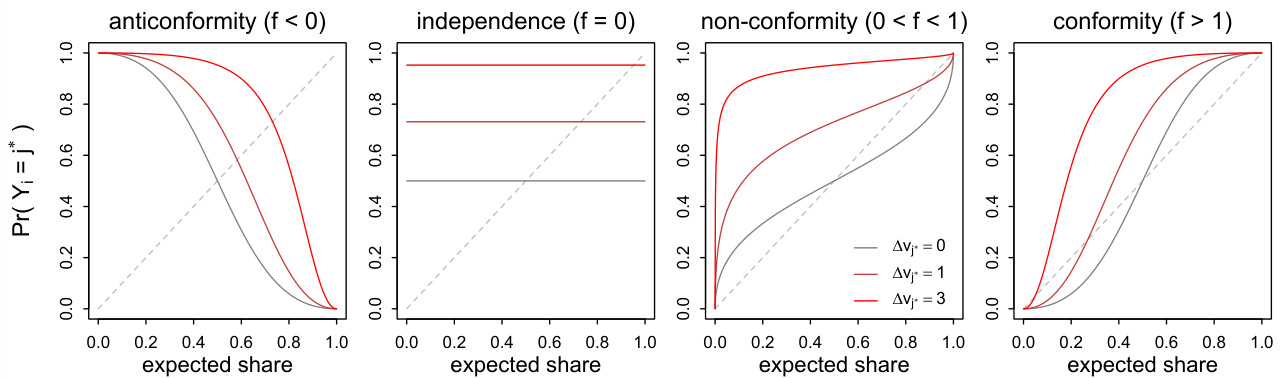
- 展示:不同社会学习参数$f$(抗趋同、独立、非趋同、趋同)与内在偏好强度$\lambda$如何影响选择内在偏好选项的概率,期望频率$s
- 趋势:
- 抗趋同者选择内在偏好选项概率随群体频率下降,反向效应明显。
- 独立者选择概率无关社会频率。
- 非趋同和趋同者选择概率随着群体频率提升而升高,且内在偏好强化倾向(概率曲线整体上移)。
- 与文本联系:
- 强化了内在偏好或先验信念作为“信息免疫剂”的观点。
- 支持社会规范动态理论的理性基础,社交行为反馈循环时存在稳定平衡。
3.3 图3:个体社会学习与信念异质性(第12页)
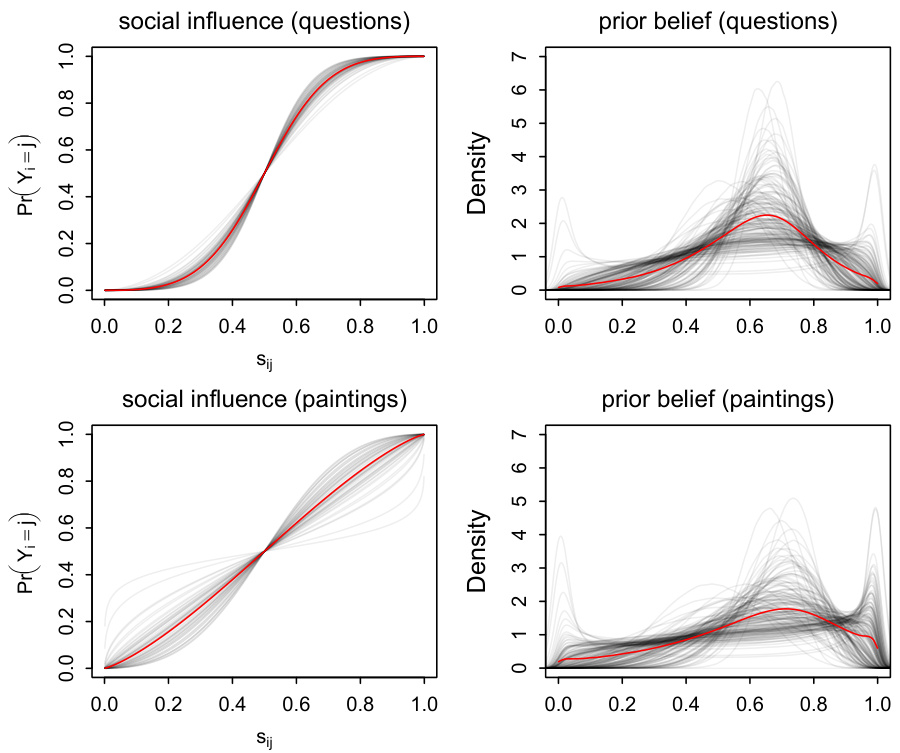
- 内容:
- 纵轴为选择内在偏好选项概率与社会期望份额$s_{ij}$的拟合曲线,黑灰散为个体估计曲线,红色为平均。
- 左上(问题任务):趋同社会学习曲线集中,个体差异小。
- 左下(绘画任务):曲线多样,分布介于顺从与反顺从之间。
- 右侧图展示先验信念密度分布,大部分个体存在倾向于偏好选项的先验偏置。
- 解释:
- 个体社会学习策略在主观任务中显著分化,表明主观任务激励多样行为模式。
- 先验偏向表明信息解读非中性,存在自我强化心理机制。
3.4 图4:激励环境对社会学习策略的影响(第14页)
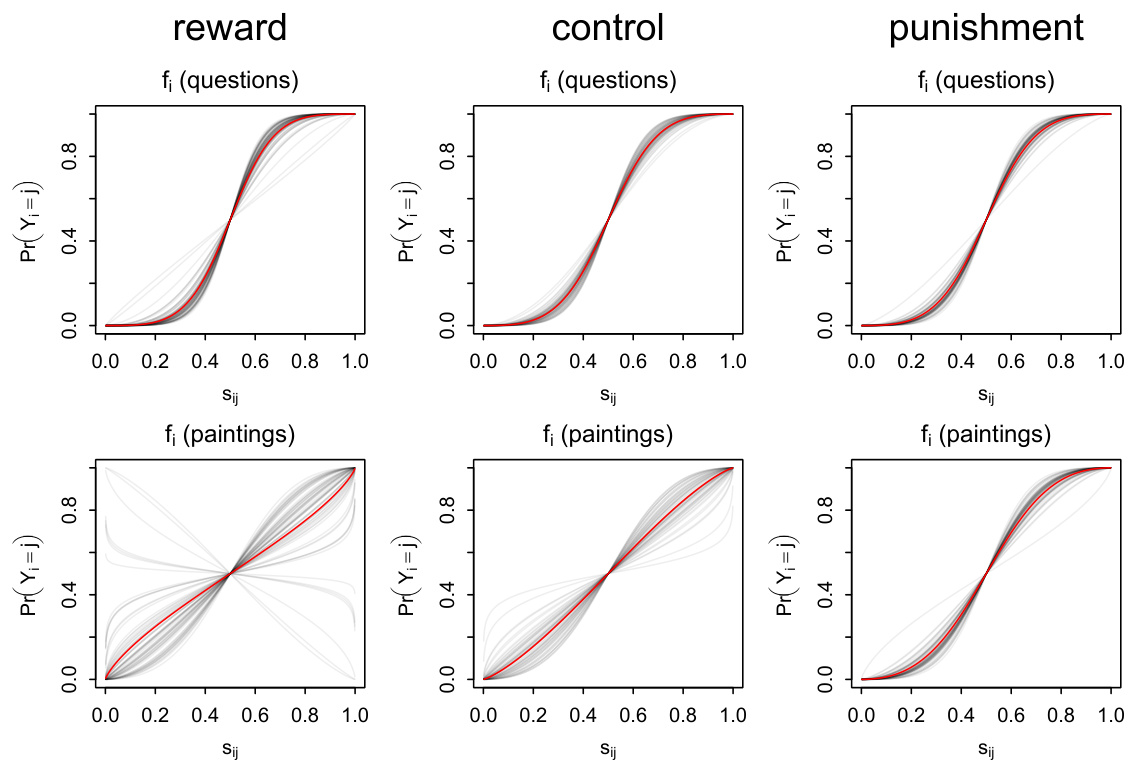
- 描述:各环境奖励、控制、惩罚对两任务中个体(灰线)和平均(红线)社会学习策略$f$变化曲线。
- 观察:
- 绘画任务中,奖励环境明显降低平均趋同性,甚至出现反趋同,惩罚环境显著提升趋同性。
- 问题任务中,三种环境全展现高度趋同,几无变动。
- 结论:
- 环境激励对主观任务中社会学习模式调整有效,反之对客观任务作用有限。
3.5 图5:模型拟合(第15页)
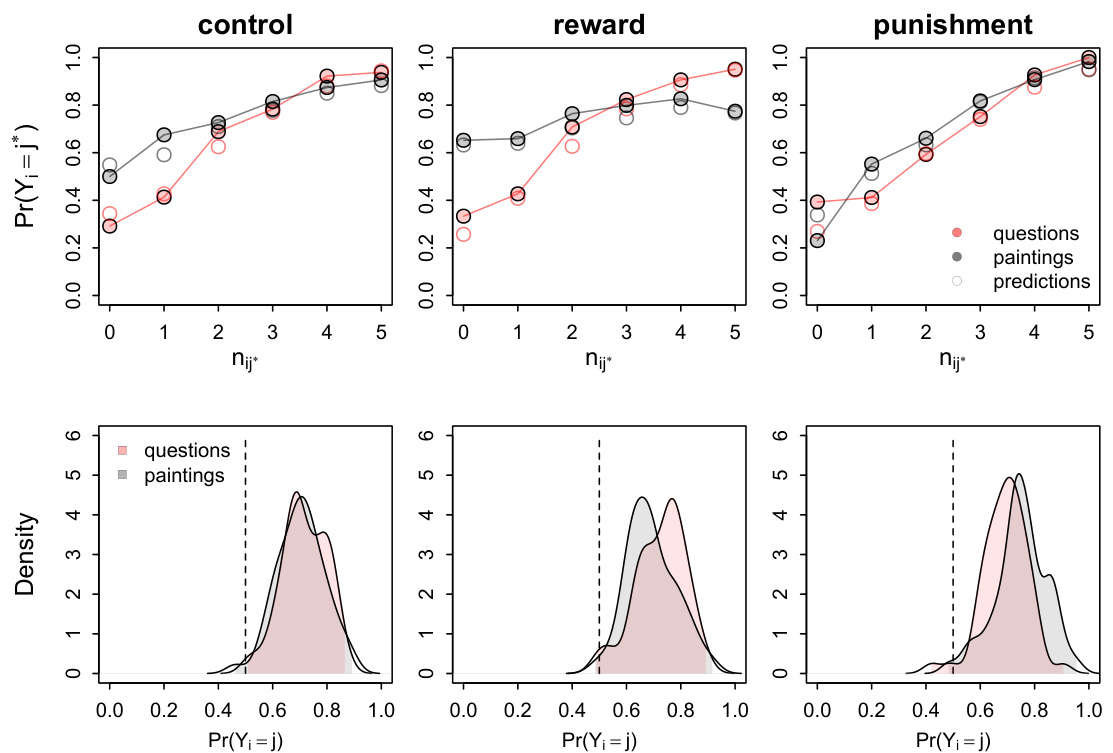
- 内容:
- 上半部分展现模型预测平均选择概率与实际观察的高度吻合。
- 下半部分显示个体层面的预测概率分布,大部分个体模型预测准确率优于随机。
- 意义:
- 表明模型不仅在群体层面可用且能捕获个体复杂的社会学习机制。
- 可靠性强,适合对人类社会学习行为建模。
3.6 图6:选择动态长时程模拟(第18页)
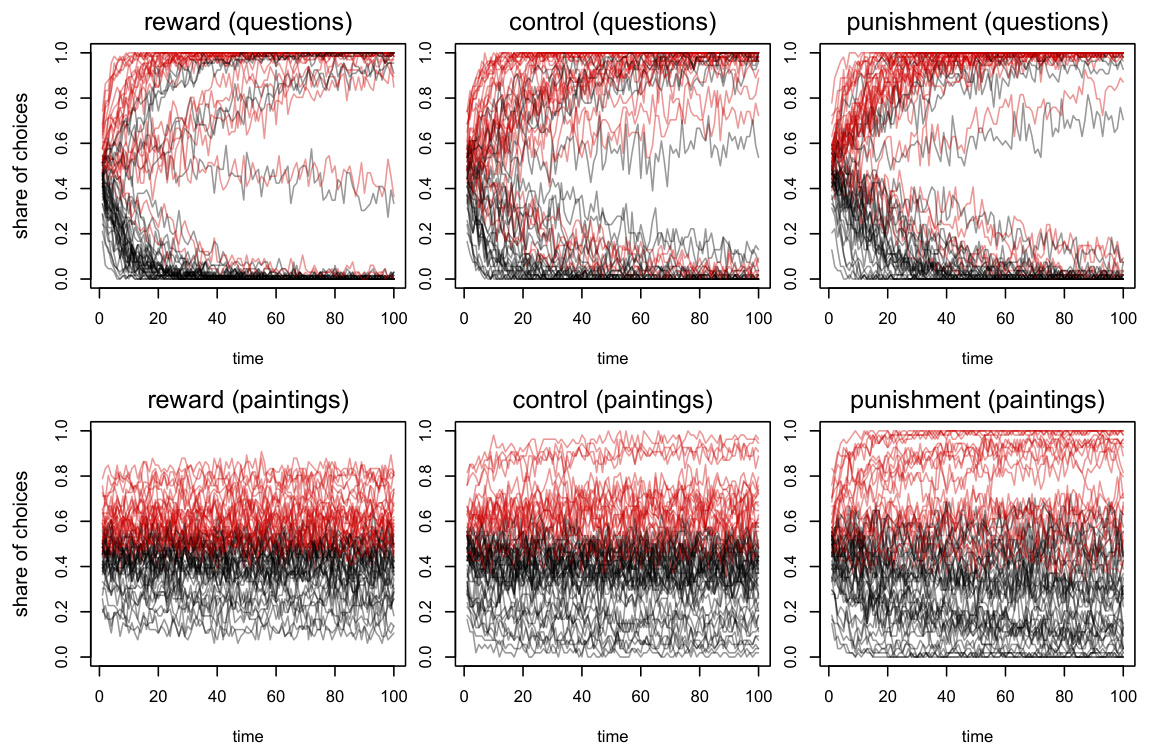
- 解读:
- 顶部三图(问题任务)显示大部分议题呈现明显收敛,红线(偏好目标选项平均偏好)趋近1,黑线趋近0。
- 底部三图(绘画任务)表现选择分布波动大,无明显收敛,尤其奖励环境选择多样,惩罚环境趋同度较强。
- 启示:
- 表明群体长期互动后,社会规范能反映出群体的内在偏好结构。
- 不同任务性质导致不同文化稳定性和偏好表达形式。
3.7 图7与图8:模拟社会规范中偏好异质性体现(第27-28页)
- 显示在有整体偏好、不同社会学习程度、先验强度条件下,多数行为偏好与实际偏好密切相关,少数极端偏好者在弱多数条件下可能导致规范逆转。
- 强化了文中观点:社会规范不仅是个体行为的平均,也是偏好力量分布的体现。
---
4. 估值分析
本报告非传统金融估值报告,未涵盖企业估值、现金流折现等内容,无相关估值分析章节,但离散选择模型参数本身相当于对个体选择“偏好效用”及“社会影响力”进行计量,体现了选择“效用价值”的计量经济学建模方式。
---
5. 风险因素评估
- 论文未专门设立“风险因素”章节,但隐含可能约束包括:
- 模型假设限制:如内在偏好和社会学习参数随时间及群体规模不变,实验中样本及环境静态。
- 实验外部效度:实验样本为大学生,线上判断任务,现实生活中社会环境更为复杂,且现实奖励可能更混合。
- 先验和偏好测量的准确性:利用隐含滑块评价,存在主观偏差和认知误差可能。
- 论文整体未给出风险缓解策略但在讨论中明确指出建模和实验设计限度,告诫读者谨慎推广。
---
6. 批判性视角与细微差别
- 模型假设的简化性:忽略了个体选择参数随时间变动和学习经验动态调整的可能,可能掩盖长期演变的复杂性。
- 任务设计的异质性解读:绘画任务虽主观,但实际偏好测量基于关联比较,存在被试理解差异可能。
- 奖励机制实际效应限定:奖励与惩罚均仅针对评估者选择,不直接基于客观正确性,可能强化了人们对评估者偏好而非客观结果的预期。
- 社会网络结构未考虑:信息来源固定为“随机5人”,现实中社交网络复杂,信息传播路劲多样,对社会学习策略影响或更深。
- 数据公布及复现:虽技术手段先进,但报告未详细说明数据来源开放性,复现度有待验证。
- 实验样本局限:大学生样本可能对个体策略选择带来偏差,且跨文化适用性未知。
- 不过整体研究设计合理,推断谨慎,结论科学。
---
7. 结论性综合
本文基于精巧的实验设计和纳入内在偏好测量的离散选择模型,成功区分了社会学习与内在偏好对个体决策的双重影响。研究发现不同任务类型和激励环境显著影响社会学习策略和偏好权重:
- 在主观性较强的绘画选择任务中,社会学习策略多样,且奖励环境激励多元化和非趋同倾向,惩罚环境强化趋同,表现为个体社会学习的极化与扩散状态;
- 在具有客观正确答案的问题选择任务中,趋同行为普遍且对激励环境敏感度较低,说明正确解任务驱动趋同形成准确的社会规范;
- 先验信念偏向及个体异质性为理解社会规范形成和个体社会学习差异提供重要视角;
- 通过长期模拟揭示密集信息反馈机制下群体行为趋于内在偏好的映射,支持社交规范并非纯粹协调利益,而包含对内在偏好的反映。
本研究架构超越了经典阈值模型,结合心理学和经济学的社会学习理论,提供强大模型和实证证据支持,此框架及结论对于理解社会规范稳定性、多样的社会影响机制及决策极化问题等具有重要影响力。
---
参考文献与附录
丰富的参考文献覆盖社会规范理论、经济学的视觉分析方法以及最新行为生态学对社会学习的研究,附录提供详细的贝叶斯建模方法及在线实验流程说明、新增模拟结果图表,保证研究透明和实证再现。
---
总结
本文在社会学习与个体内在偏好权衡领域做出创新型贡献,通过设计新颖的实验及模型,有效识别两者在不同环境和任务下的相对作用,揭示了社会学习策略的多样性及环境诱导下的行为形态变化。研究结果不仅丰富了社会影响理论,也为政策制定及行为引导提供科学依据,特别是激励机制在塑造趋同或多样化行为中的角色。报告的分析精细、建模严谨且论证充分,是理解人类社会行为复杂性的典范研究。[page::0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20]




