OpenAI发布o3-pro Mistral推出推理模型Magistral AI动态汇总20250616【中邮金工】
创建于 更新于
摘要
本报告集中介绍OpenAI最新o3-pro推理模型、法国Mistral的Magistral推理模型及Meta的LlamaRL强化学习框架等AI前沿技术动态。详细剖析o3-pro在多个基准测试中的领先性能及价格策略,Mistral基于纯强化学习的推理优化及多语言支持,Meta基于异步分布式架构显著提升模型训练效率。此外,报道AMD推动AI芯片升级及中国玉盘AI推出创新SRDA架构,展示算力和架构革新趋势,为AI技术产业应用提供全面参考[page::0][page::2][page::3][page::4][page::5][page::6][page::9][page::10].
速读内容
OpenAI发布o3-pro推理模型 [page::1][page::2]

- o3-pro以逐步拆解问题方式提升对复杂数学、科学和编程任务的推理能力。
- 在AIME 2024数学测试中,o3-pro准确率最高达93%,并在博士级科学测试和编程竞赛表现领先对手。
- 价格相较前代模型下降87%,支持多模态输入与长达20万token的上下文窗口。
- 存在响应速度较慢等局限,适合高可靠性复杂场景使用。
Mistral推出Magistral推理模型系列 [page::3][page::4]

- Magistral系列采用纯强化学习(RL)训练,摒弃人类反馈蒸馏,提升推理表现。
- Magistral Medium在AIME-24测试准确率跃升至73.6%,多投票策略下达到90%。
- 引入“推理语言对齐”技术实现结构化思考步骤,支持8种语言母语级推理。
- 小参数版本开源,企业版商业化,推理速度领先主流竞品10倍,适用于金融和法律合规等场景。
Meta发布LlamaRL强化学习框架 [page::4][page::5][page::6]

- LlamaRL采用全异步分布式架构,训练4050亿参数模型效率提升10.7倍,训练时间降至59.5秒。
- 通过分离生成与训练GPU集群、CUDA Graph流水线和DDMA内存访问,实现资源高度优化及通信开销降低90%。
- 加速过程不牺牲模型效果,在数学推理测试上表现稳定。
- 芯片依赖性和小模型收益递减为主要限制,开源部分代码推动社区生态建设。
AMD Advancing AI 2025大会亮点 [page::6][page::7]

- 发布基于3nm工艺的Instinct MI350系列GPU,推理性能提升35倍,训练性能提升4倍。
- 288GB HBM3E显存和Infinity Fabric实现超大显存池化,效能与能耗表现优异。
- ROCm 7软件栈支持FP8数据类型,跨平台迁移友好,提升整体AI计算性能。
- 深度合作OpenAI及顶级超算案例展示实际应用价值。
中国玉盘AI发布SRDA架构颠覆传统算力 [page::9][page::10]

- SRDA基于数据流驱动设计,从硬件底层解决算力利用率低、内存瓶颈与功耗高问题。
- 采用分布式3D堆叠内存和全链路高速互联,内存访问延迟降低60%,带宽利用率提升至95%。
- 适应主流模型动态重构计算路径,单位算力功耗降低62%,集群建设成本削减40%。
- 面临生态培育和兼容性挑战,已获甲骨文等大客户支持,目标构建AI算力新基础设施。
AI大模型挑战与前沿研究综述 [page::11][page::13]
- 2025年高考数学成为AI模型能力试金石,DeepSeek R1夺冠,讯飞星火紧随,GPT o3等表现优异但存在多模态短板。
- 不同模型在解题速度和推理步骤规范性有显著差异,算法优化对实用性影响显著。
- 学术论文《The Illusion of Thinking》通过算法谜题实验揭示当前大模型推理存在“思考幻觉”和计算缩放限制,建议结合符号系统探索更优推理架构。
深度阅读
OpenAI发布o3-pro,Mistral推出推理模型Magistral AI动态汇总20250616【中邮金工】报告详尽分析
---
1. 元数据与报告概览
- 报告标题: OpenAI发布o3-pro,Mistral推出推理模型Magistral AI动态汇总20250616
- 作者: 肖承志、冯昱文
- 发布机构: 中邮证券有限责任公司
- 发布日期: 2025年6月17日
- 报告主题: 主要聚焦近期AI大语言模型(LLM)相关重点事件,包括OpenAI最新推理模型o3-pro的发布,法国Mistral AI推理模型Magistral系列的面世,Meta公司发布的LlamaRL强化学习训练框架,以及AMD在AI硬件领域的重大突破。
核心信息:
报告对四大前沿事件进行系统梳理和动态汇总,强调o3-pro和Magistral在推理能力方面的突出表现,Meta在训练效率上的革命性进展,以及AMD硬件和生态的全面升级。旨在揭示AI推理技术和算力基础设施的最新发展态势与未来趋势,具有重要的行业指引价值。
---
2. 逐节深度解读
2.1 摘要章节
- OpenAI发布o3-pro:新发布的AI推理模型o3-pro被官方称为“迄今最强大的AI模型”,相较前代o3,o3-pro专注于深度逻辑思考和高可靠性响应,尤其适用于数学、科学、编程等领域。强调其推理模型特点,即非传统模式匹配,而是逻辑拆解问题、逐步推导结论。[page::0-1]
- Mistral推出Magistral:法国Mistral AI首个聚焦推理的LLM产品,核心设计为“透明推理”和“多语言链式思考”。通过纯强化学习框架(非传统RLHF)提升推理能力,并采用开源+商业双轨制,实现技术与市场的差异化布局。[page::0-1]
- Meta LlamaRL框架:Meta新型强化学习训练框架大幅提升大模型训练速度(10.7倍),通过异步分布式架构创新解决资源和内存瓶颈,实现算力成本和训练效率的革命。[page::0-1]
- AMD大会:AMD发布的Instinct MI350 GPU及ROCm 7软件生态布阵,标志硬件技术飞跃和生态开放竞争新阶段,有望挑战英伟达的市场地位。[page::0]
2.2 1.1 OpenAI发布o3-pro
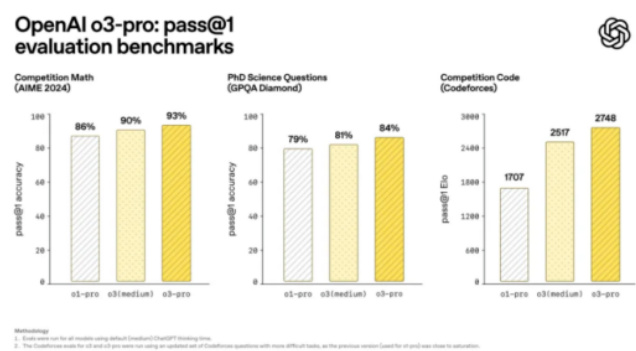
- 关键内容: o3-pro升级自o3,加入“推理模型”特性,核心优势为逐步逻辑分析和分解复杂问题,避免依赖传统模式匹配。采用“4/4可靠性”标准,要求模型多次答题均正确,数学(AIME 2024)、科学(GPQA Diamond)及编程(Codeforces)测试中均优于谷歌 Gemini 2.5 Pro 和Anthropic Claude 4Opus。[page::1]
- 性能与成本: 支持多模态输入(文本+图像),极长上下文窗口(20万token),带工具调用能力。API价格降87%,输入每百万token 20美元,输出80美元,较前代有明显成本优势,策略意在降低技术门槛和应对竞争。
- 限制与反馈: 响应速度慢,简单任务延迟高(如4分钟),临时聊天禁用,图像生成功能缺失,部分用户对长上下文能力表现认可,但延迟和兼容性限制受诟病。[page::2]
- 图表解读(图表1-4):
- 图1显示o3-pro在多项测试中的性能领先,数学准确率达93%,博士科学问题84%,代码竞赛积分2748分,均显著优于前代。
- 图2表明o3-pro相比o1-pro的成本大幅降低,输出token价格降至80美元/百万,输入仅20美元/百万。
- 图3“4/4可靠性”数据中,o3-pro达90%+的高可靠性,进一步验证模型稳定性。
- 图4ATC-AGI榜单显示o3-pro在人工智能通用智能水平排行榜中的优势表现。
- 战略意义:OpenAI快速迭代策略(o3到o3-pro仅两个月)、多云算力合作布局(减少对微软依赖)、更专业化应用定位(高可靠性、复杂场景)是其核心要点。[page::2]
2.3 1.2 Mistral推理模型Magistral
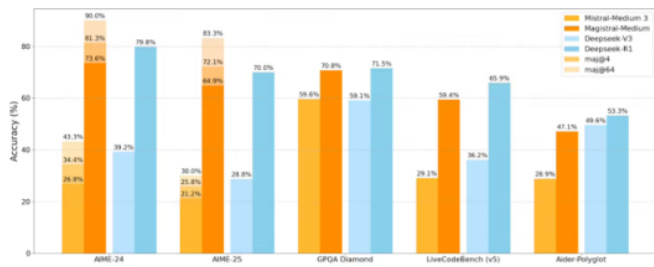
- 训练与框架创新: 采用纯强化学习(RL)框架,创新性剔除RLHF对人类反馈蒸馏依赖,使用Group Relative Policy Optimization (GRPO)算法动态调节探索阈值,配合异步分布式训练架构,极大提升数学与编程推理表现。[page::3]
- 性能表现: Magistral Medium在AIME-24数学准确率从26.8%跳升至73.6%,多数投票策略达90%;多模态理解任务提升12%;支持八种语言母语级推理,提高跨语种一致性。
- 版本结构:
- Magistral Small (24B参数) 开源,Apache 2.0许可,服务研究与中小企业。
- Magistral Medium 闭源,企业版本,速度快至每秒1000 tokens,适合金融智能客服等高频应用。
- 应用案例: 供应链交付优化、金融风控、法律审计、医疗诊断、非英语代码注释等领域展现透明推理优势。
- 质疑与限制: 基准测试范围未涵盖全部顶尖开源模型;企业版本闭源引发社区争议;科学任务深度表现上有差距于谷歌Gemini等顶尖竞品。[page::3-4]
- 行业意义: 反映AI领域正从规模竞争转向效能优先,以推理效率代替参数盲目扩充。Mistral定位“用用户语言思考”,努力解决大模型多语言场景适用瓶颈,嵌入欧盟技术生态主权竞争。[page::4]
2.4 1.3 Meta发布LlamaRL强化学习框架
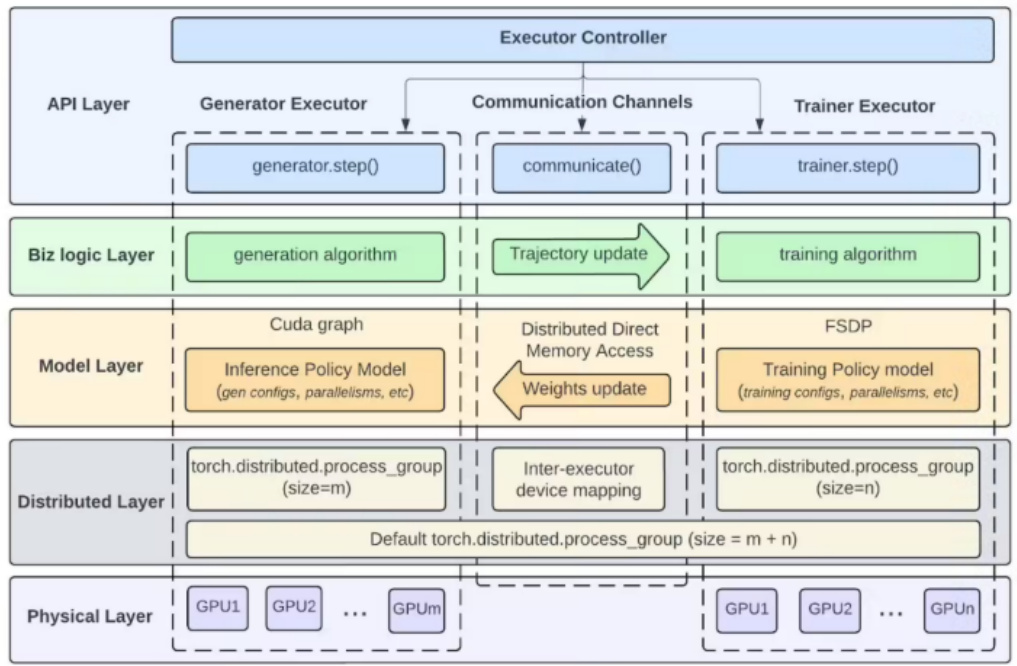
- 架构与技术突破: LlamaRL采用全异步分布式架构,通过Generator Executor、Trainer Executor并行化任务,利用CUDA Graph预编译和DDMA直连内存访问技术极大降低通信开销,实现4050亿参数模型强化学习训练时间由635.8秒缩短至59.5秒,速度提升10.7倍。[page::4-5]
- 技术细节解析:
- 资源调度上划分生成与训练GPU集群,避免资源抢占。
- 内存消耗降低37%,显著缓解内存瓶颈。
- 计算流水线化布局,将推理-训练-奖励过程转化连贯计算图,最大限度减少延迟。
- 性能与质量平衡: 在MATH、GSM8K等数学推理测试中,训练速度提升未牺牲模型性能,异步机制不会产生噪声或偏差。
- 局限: 对硬件依赖偏重(NVLink、DDMA),在非NVIDIA平台适配性未知;对新型强化学习算法支持有限;异步加速效果在小参数模型中递减。
- 生态与未来路线: Meta计划结合超级集群“RSC-X”提供云端强化学习平台,推动AI模型持续进化和具身智能发展。LlamaRL或成为未来万亿参数以上模型训练基石。[page::6]
2.5 1.4 AMD举办Advancing AI 2025大会
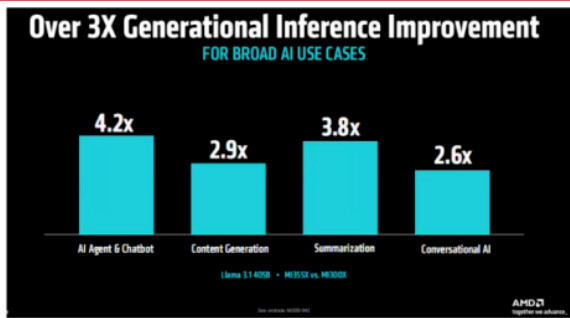
- 硬件创新: Instinct MI350系列GPU基于台积电3nm制程CDNA 4架构,集成1850亿晶体管,单卡性能相比MI300X整体推理提升35倍,训练提升4倍。[page::6-7]
- 关键技术进展:
- 超大容量288GB HBM3E内存,显存池化技术实现多GPU共享8TB统一显存。
- 新支持异构多精度(FP4/FP6/FP8),配合ROCm 7软硬件生态优化推理性能。
- 性能指标超过英伟达B200/G200方案30%以上。
- 未来芯片路线: MI400系列2026年预计出货,将配备432GB HBM4,带宽19.6TB/s,40PFLOPS FP4算力,专为万亿参数模型设计。
- 软件生态升级: ROCm 7软件栈支持CUDA无缝迁移与主流框架,提升3倍推理性能,3倍训练性能,推助开发者生态繁荣。
- 战略合作及生态优势: 与OpenAI协同打造Owl-2视觉模型硬件适配,Meta和甲骨文等大客户积极部署,推动云端和超算合作。
- 挑战: 软件生态惯性(CUDA领先优势)、未量产新技术工艺成熟度、英伟达Blackwell方案仍有微小性能优势。
- 产业意义: AMD构建云端到终端的全套AI计算解决方案,推动AI硬件多元竞合与可持续发展。[page::7-8]
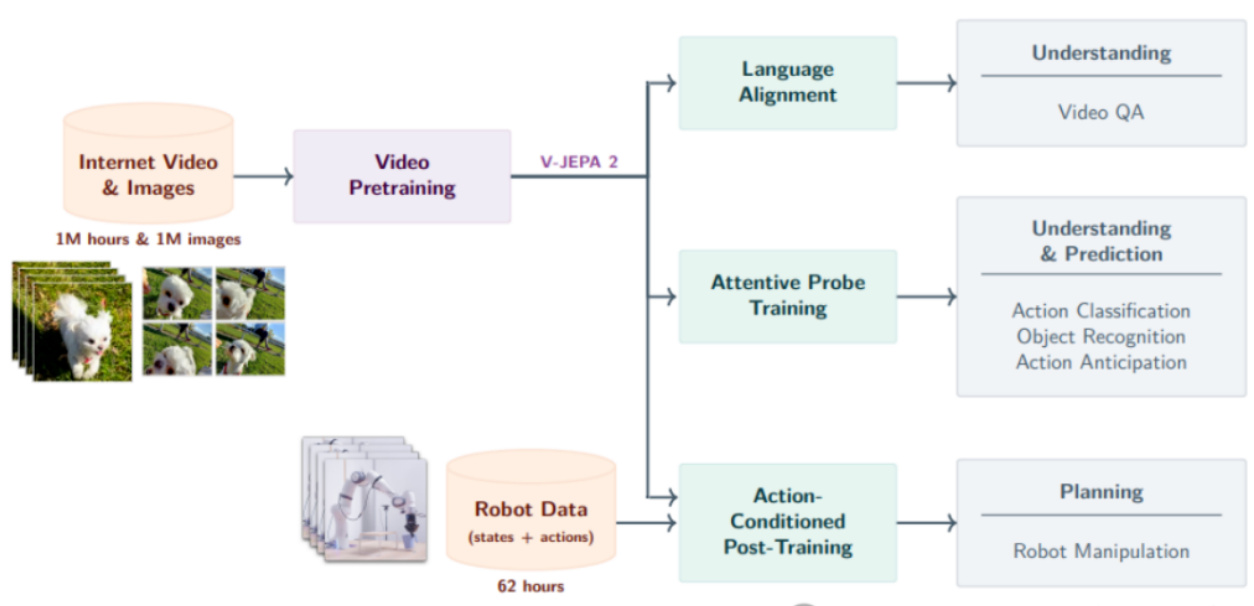
2.6 2.1 Meta推出世界模型V-JEPA 2
- 背景与创新: Meta的V-JEPA 2采用联合嵌入预测架构( JEPA ),通过从上百万小时视频与图像中自监督学习,抽象物理规律,提升物理世界的理解和预测能力。[page::8]
- 双阶段训练:
- 无动作预训练通过掩码去噪学习运动、重力等物理常识。
- 动作条件微调利用机器人操作数据实现零样本规划。
- 性能与优势: 在机器人操作成功率和物理推理基准中,明显优于传统基线与现有视觉编码器,实现多任务高效统合。
- 创新成果: 物理推理榜单领先GPT-4o及Gemini 1.5 Pro,展现“类人直觉”;能够支持复杂动作预判和机器人自主操作,拓展AI现实场景应用边界。
- 技术路径图(图表11): 视觉预训练结合语言对齐、重点探测训练与动作条件规划,形成统一世界模型框架。
- 战略意义: 推动AI范式从纯语言理解迈向物理直觉认知,提升真实世界自主智能水平。[page::9]
2.7 2.2 玉盘AI推出SRDA架构
- 设计理念: SRDA将AI计算架构从传统GPGPU的控制流模式转向“数据流驱动”,通过软硬件深度融合,实现数据沿计算图依赖方向点到点传输,避开共享内存瓶颈致使的算力浪费。[page::9-10]
- 关键技术突破:
- QDDM分布式3D堆叠内存技术配合带宽隔离,实现60%内存延迟降低,带宽利用率提升至95%。
- QLink融合网络技术提供单层all-to-all通信,协议开销减少80%,大规模集群通信效率比传统方案高4倍。
- 可重构数据流引擎支持模型架构动态映射,适配Transformer及新兴模型需求。
- 实测表现: 推理Llama 3.1 405B模型算力利用率78%,功耗降低62%。
- 商业价值: 总拥有成本(TCO)较NVIDIA H100方案低40%,适合模型架构趋同后的性价比竞争。
- 生态挑战: 面对CUDA生态惯性、3D-DRAM良率风险、传统网络兼容性及边缘场景适配等问题。
- 发展愿景: 计划开源架构白皮书,推进边缘计算,挑战AI算力垄断,为AGI时代算力普惠化提供中国方案。
- 图表12-13清晰对比SRDA与传统GPU架构瓶颈与优化点。[page::10-11]
2.8 3.1 七家主流大模型挑战2025高考数学
- 测评方法: 由七家主流AI模型以多版本交叉试题及专家评分,测试多步骤逻辑推理能力,涵盖选择、填空与解答题,侧重复杂数学推理能力。
- 测评结果:
- DeepSeek R1(143分)与讯飞星火X1(141分)领先。
- GPT o3得138分,国产模型与国际水平拉近。
- 谷歌Gemini 2.5 Pro最高达145分。
- 模型表现亮点: DeepSeek完整推理链条清晰,讯飞星火在解题步骤规范符合阅卷标准。国产模型算法优化和教育数据积累展现优势。
- 限制与瓶颈: 多模态能力不足导致图像题完全失分;部分模型推理指数不稳定或跳步;部分强推理模式耗时长,实际应用受限。
- 技术启示: 小模型推理效率与准确性兼备重要性日益突出;强化学习稳定性及验证机制需加强。[page::11-12]
4. 技术前沿
4.1 Apple发布“The Illusion of Thinking”论文解读
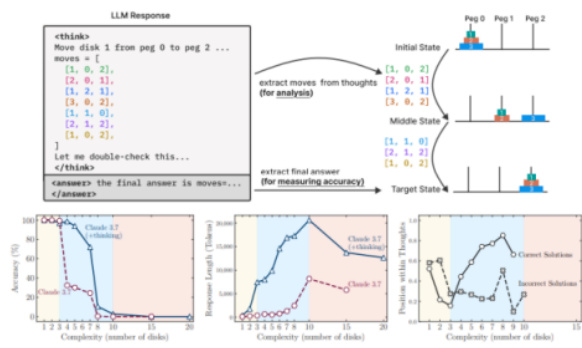
- 研究背景: 通过设计算法谜题(河内塔、跳棋、河流穿越、积木世界)控制复杂度,细粒度分析大语言模型推理路径及过程结构,超越传统仅看最终答案准确率的评测方式。
- 方法创新: 使用动态分析工具量化推理路径中间步骤位置及正确率,以及与问题复杂度相关的表现。
- 核心发现:
- 不同问题复杂度对应三类推理模式,低复杂度下非思考模型表现较好,中复杂度下思考模型优势明显,高复杂度均崩溃。
- 模型存在“过度思考”现象,即早得正确答案仍无效继续探索,推理路径存在效率低下。
- 强化学习覆盖能力并未显著提升泛化推理,暗示现有LRMs多以记忆而非真正的符号推理为核心。
- 研究意义: 揭示了现有大型语言模型“思考幻觉”的客观规律,挑战了普遍对AI推理能力质的提升认知,强调需新的算法设计与验证机制方能实现质变。
- 图表15-16生动展示了推理路径可视化及复杂度对应的准确率和推理长度变化。
- 启示及建议: 需开发更鲁棒验证及混合推理架构,构建干净评估基准,切实突破符号计算与神经网络泛化的结合难题。[page::12-14]
---
3. 图表深度解读
- 图表1-4(OpenAI o3-pro表现与价格对比):清晰展示o3-pro在多个专业基准测试中的高准确率与可靠性,尤其在数学、科学和编程领域领先其它同类模型,且价格大幅下降与性能提升形成背书。
- 图表5-6(Magistral模型评测跑分及不同训练方式比较):揭示纯强化学习训练显著提升模型数学与编程任务表现,该方法对多模态任务也有促进作用,且相比传统微调与RLHF混合方式更优。
- 图表7-8(LlamaRL架构与性能对比):图表7展示了LlamaRL分层异步架构,支持多GPU高并行易扩展;图表8表明LlamaRL在提升训练速度的同时,保持或轻微提升模型性能。
- 图表9-10(AMD MI350系列性能跃迁):展示新一代GPU在推理、内容生成等多个AI应用场景中的性能提升均超过2.6倍,且参数配置和带宽方面优于竞品,体现硬件优势。
- 图表11(Meta V-JEPA2架构图):全流程涵盖海量视频预训练到动作条件微调,复合多阶段训练策略确保模型物理推理和控制能力双提升。
- 图表12-13(SRDA架构及算力需求对比):强调传统GPGPU架构在算力和效率上的瓶颈,SRDA通过数据流设计和3D堆叠内存技术显著改善性能指标,有效填补算力需求缺口。
- 图表15-16(Apple论文推理行为):通过谜题推理路径与复杂度映射,展现模型推理的非线性衰减及“虚假思考”行为模式,提供全新评估视角。
---
4. 风险因素评估
- 市场政策变化风险:报告基于历史数据,市场环境和政策变动可能导致推断失效。
- 技术迭代和竞争风险:AI技术快速更替,如开源模型的突发进步,可能改变行业格局。
- 硬件生态适配风险:如AMD等非NVIDIA平台生态建设难度,制程技术良率风险。
- 模型性能及安全风险:推理模型在实际采用中仍存在响应速度延迟、推理准确率极端依赖训练数据等问题;强化学习算法的泛化能力和安全性尚不完善。
- 商业模式及开源策略风险:Mistral的双版本策略可能在社区支持和市场接受度上存在不确定性。
- 算力成本与资源依赖风险:Meta LlamaRL的高度硬件依赖限制普及,模型训练环境受制算力资源。
报告对上述风险均作了提示,但具体缓解策略讨论较为有限。[page::0,14]
---
5. 批判性视角与细微差别
- 潜在偏见:报告更多突出技术进步和性能指标,较少对模型应用中的伦理、数据偏见和安全性等难题深入批判。
- 速率与成本权衡未充分量化:OpenAI o3-pro的响应延迟问题被提及,但未详述其对用户体验和潜在业务的具体影响。
- 生态挑战辨析待深化:AMD及SRDA等硬件方案面临生态惯性,报告提及但未深入策略层面分析。
- 基准对比有局限:Mistral未与某些同期顶尖开源模型的性能做广泛横评,存在选择性展现的风险。
- 推理能力评价复杂性:Apple“思考幻觉”提出的模型推理非线性衰退和过度思考现象,提示大模型推理能力仍处于概念验证阶段,需与行业主流观点综合考量。
- 内部逻辑一致性良好,整体报告结构严谨,论据充分,证据链清晰,且配套图表支持文本分析。
---
6. 结论性综合
本报告系统梳理了2025年6月AI领域四大重要技术事件,展现了语言模型推理能力和训练效率的最新突破:
- OpenAI o3-pro凭借其推理模型技术,在数学、科学和编程等严谨逻辑领域表现出行业顶尖水平,结合成本骤降策略,强化了行业领先地位,尽管存在响应时延等实用局限。
- Mistral Magistral系列在推理训练范式上创新引入纯强化学习架构,实现数学与编程推理显著跃升,适应多语言环境并通过开源商业双轨模式,体现了在欧洲和全球市场构筑技术主权和差异化竞争的战略意图。
- Meta LlamaRL强化学习框架则代表了AI训练基础设施的技术革命,通过架构上的异步分布设计和高效硬件通信技术,大幅降低算力成本和训练时间,提升了模型迭代速度和安全对齐能力,为大规模、多模态AI训练奠定基础。
- AMD硬件与生态深耕体现了从硬件芯片工艺到软件生态的系统性升级,MI350及未来MI400方案的高性能与能效特性,加上ROCm的生态开放,标志着AI计算设备多极化、新范式时代的开启。
- 附加创新:Meta V-JEPA 2世界模型推进AI向物理认知迈进,玉盘AI SRDA架构以创新数据流思维重塑计算体系,加速突破算力瓶颈,强化了AI算力自主权可能。
- 行业洞察:七大主流模型在高考数学测试中成绩拉近,显示国产与国际模型的竞争激烈和推理能力提升,但同时暴露了多模态融合、实时性及逻辑稳定性等实际应用瓶颈。
- 理论研究视角:Apple团队揭示大模型推理过程中存在的“思考幻觉”与非线性故障模式,为未来模型设计和评估方式提供了科学、细粒度的参考范式。
结合各模型及技术图表,报告展示了从推理模型准确率、成本效率、训练速度、硬件性能到多模态物理理解的多维度飞跃,反映AI推理技术已进入新的竞争和创新周期,但仍面临生态建设、响应时效、深度推理能力以及硬件适配的系统挑战。
总体来看,报告对AI产业关键技术发展提供了理性、深入的视野,有助于投资者和行业参与者更好理解当前趋势与潜在风险,支持科学决策。[page::0-14]
---
参考图片(部分)
-
-
-

---
【来源依据页码见正文对应页尾标注】




