随机森林与传统多因子模型的选股风格对比
创建于 更新于
摘要
本报告基于沪深300、中证500及全A股样本,采用机器学习的随机森林算法构建多因子选股模型,并与传统线性回归多因子模型进行比较。结果显示,随机森林模型在各样本池均优于传统模型,特别是在2014年和2017年市场风格切换期表现出更强的灵活性,能更快捕捉市场转向。此外,随机森林模型的因子暴露较传统模型更为稳定,收益来源较分散,避免了传统模型极端化选股风格的问题。建议实际应用中结合风险模型控制市值因子暴露,缓解因子失效风险。未来研究将探索更多机器学习算法和因子处理方法 [page::0][page::4][page::9][page::11][page::20][page::21]
速读内容
- 模型构建方法概述 [page::0][page::4][page::9]
- 随机森林模型选取沪深300、中证500和全A股成分股,采用过去12个月数据训练模型,预测下月股价上涨概率,选取上涨概率最高的50只股票。
- 传统多因子模型基于8大类因子(估值、盈利、成长、动量、反转、波动率、流动性、市值)用线性回归建立收益预测模型。
- 随机森林模型优势突出,特别是在市场风格转换期表现更佳 [page::11][page::15][page::18]



- 沪深300样本中,随机森林年化收益提升1.75%,月度胜率提升5%;
- 中证500样本中,波动率降低1%,月度胜率提升6%;
- 全A股样本中,年化收益提升3%,月度胜率提升4%。
- 2014年和2017年市场风格转换阶段,随机森林模型能更快捕捉风格切换,带来超额收益。
- 业绩归因分析显示随机森林模型因子暴露更稳定、收益来源更均衡 [page::11][page::15][page::18][page::20]
| 样本范围 | 因子暴露波动率对比 | 传统模型主要收益因子 | 随机森林模型主要收益因子 |
|--------------|-----------------------------|------------------------------|--------------------------------|
| 沪深300 | 传统模型波动率约为随机森林2倍 | 市值、估值 | 市值、估值、流动性较均衡 |
| 中证500 | 传统波动率明显高于随机森林 | 市值、流动性、波动率 | 流动性、波动率、估值 |
| 全体A股 | 传统模型因子暴露绝对值明显更大| 市值、流动性、反转 | 市值、流动性、估值 |
- 传统模型因子暴露极端,市场回撤期表现较差。
- 随机森林模型对动量和反转因子有差异倾向,更善于捕捉短期反转因子信号。
- 因子历史暴露趋势图展示(沪深300样本) [page::12][page::13]



- 市值因子波动明显,传统模型更激进。
- 随机森林在反转因子上的负收益,传统模型在动量因子上出现负收益,显示两者风格分歧。
- 因子历史暴露趋势图展示(中证500和全A股样本) [page::16][page::19][page::20]



- 随机森林模型对市值因子暴露控制更为谨慎,传统模型往往因暴露过大导致收益波动加剧。
- 风险控制与未来研究方向 [page::20][page::21]
- 建议传统多因子模型结合风险模型控制整体组合风险,以免因过度极端暴露带来回撤。
- 强调市值因子风险控制,防范因子失效可能带来的大幅回撤。
- 未来拟探索Boosting、SVM、神经网络等更多机器学习算法。
- 计划结合收益模型与风险模型,完善因子预处理方法,及行业轮动与细分多因子模型融合。
深度阅读
对《随机森林与传统多因子模型的选股风格对比》报告的详尽分析
---
1. 元数据与概览
- 报告标题:随机森林与传统多因子模型的选股风格对比——一多因子模型研究系列之四
- 分析师:宋肠
- 发布机构:渤海证券股份有限公司
- 发布日期:2018年7月26日
- 核心主题:本报告围绕机器学习方法中的随机森林算法与传统线性回归多因子模型在中国A股市场中的选股效能与风格比较,重点分析两种模型在沪深300、中证500及全体A股三个样本池的表现差异及因子暴露特征。
- 核心观点:
- 随机森林多因子模型在所有样本池中的表现均好于传统多因子模型,特别是在市场风格转换期拥有更强的灵活性和适应性。
- 传统多因子模型在因子暴露上的波动性明显更大,表明其选股风格更为激进和极端。
- 股票小市值比例增高(如全A>中证500>沪深300)时,因子波动性和市值因子暴露度均上升,提示需风险管控。
- 建议对市值因子风险敞口进行控制,防范因子失效风险。
- 目标:通过比较两种模型的回测收益与因子风格,验证随机森林在多因子选股中的可行性与优越性,并探索未来改进方向。[page::0,4,9,20]
---
2. 逐节深度解读
2.1 概述(1.概述)
- 传统多因子模型通过截面线性回归,假设因子与未来股票收益存在线性关系,在中国A股长期实践中成效显著。
- 2017年以来,市场风格大幅变化,传统模型表现回落,亟需更灵活高效的预测技术。
- 随机森林算法具有直观、参数少、抗噪声与过拟合能力强等优势,前期已成功应用于行业轮动模型。
- 本报告旨在将随机森林引入多因子选股模型,以期提升模型的适应性和表现。[page::4]
2.2 模型建立方法(2.1-2.3)
- 因子提取:不同于传统模型须规避多重共线性,随机森林可同时利用多达91个小因子,涵盖估值、盈利、成长、动量、波动率、流动性、市值及反转8大类,包含BarraCNE5手册绝大多数因子。
- 数据预处理:包括数据对齐(考虑财报发布时间滞后避免未来数据泄露)、中位数去极值及缺失值处理(用对应行业中位数替代)、ZScore标准化以及行业市值中性化处理(用回归残差剔除行业和流动市值影响)。
- 样本设计:
- 样本池: 沪深300、中证500、全A股,剔除ST/PT及上市未满两年股票。
- 时间区间: 2010.01-2018.06,按月提取因子。
- 模型构建:
- 随机森林模型:每月月底截面,选取未来月收益排名前后30%股票为正负例,汇聚过去12个月训练数据训练模型,预测未来月股票涨跌概率,选中概率最高的50只成份股,等权组成组合。
- 传统多因子模型:利用上述八大类因子的12个月移动平均收益预测,通过多元线性回归建模选股,方法详见早期相关报告。
- 业绩归因模型:采用传统八大因子定义测算因子暴露与因子收益([\((w-wb)Xf^T\)]及[\((w-wb)Xf^Tr_f\)]),对比两模型的选股风格(因子暴露)与收益成分。
- 剔除交易限制(停牌、涨停)因素,保证回测的实际可交易性。[page::4,8,9]
2.3 回测结果(3.1-3.3)
3.1 沪深300样本池
- 收益表现:随机森林模型年化收益较传统模型高出1.75%,月度胜率提升5%。
- 分年度表现:
- 2010-2012与2016-2018年,随机森林模型略逊于传统模型。
- 2013-2015年,随机森林显著优于传统模型。
- 图2-3解读:
- 收益曲线显示2014年市场风格转折期,随机森林模型快速响应,实现收益超越。
- 对冲基准收益曲线进一步表明随机森林在风格切换中适应性强。
- 因子风格表现:
- 表4显示,传统模型因子暴露波动率约为随机森林的两倍,风格更为激进极端。
- 传统模型选股收益集中于市值与估值因子,而随机森林收益分布较平均。
- 细因子维度,两个模型在市值、成长、盈利等五大类因子暴露较为一致,传统模型暴露幅度较大。
- 在动量和反转因子上两模型现出风格分歧:随机森林更能捕捉短期反转信号(反转因子收益为负),传统模型更侧重长期动量信号(动量因子收益为负)。
- 图4-11展示了上述因子暴露的时间演变,二者呈周期性波动但随机森林波动幅度较小。[page::10-13]
3.2 中证500样本池
- 收益和风险指标:
- 随机森林模型波动率比传统模型低1%,月度胜率提升6%。
- 分年度收益:
- 2010-2013年随机森林表现略差。
- 2013-2018年随机森林明显领先,尤其2014和2017年风格转弯期表现优异。
- 图12-13显示,随机森林整体收益曲线优势明显,且胜过基准指数。
- 因子风格差异:
- 传统模型因子暴露波动率依然明显大于随机森林。
- 传统模型的收益主要来自市值、流动性、波动率因子。
- 随机森林的收益主要来自流动性、波动率和估值因子。
- 在市值因子暴露上,2010-2013年传统模型给出大幅负暴露,随机森林表现保守,或因传统模型部分跑输的原因。
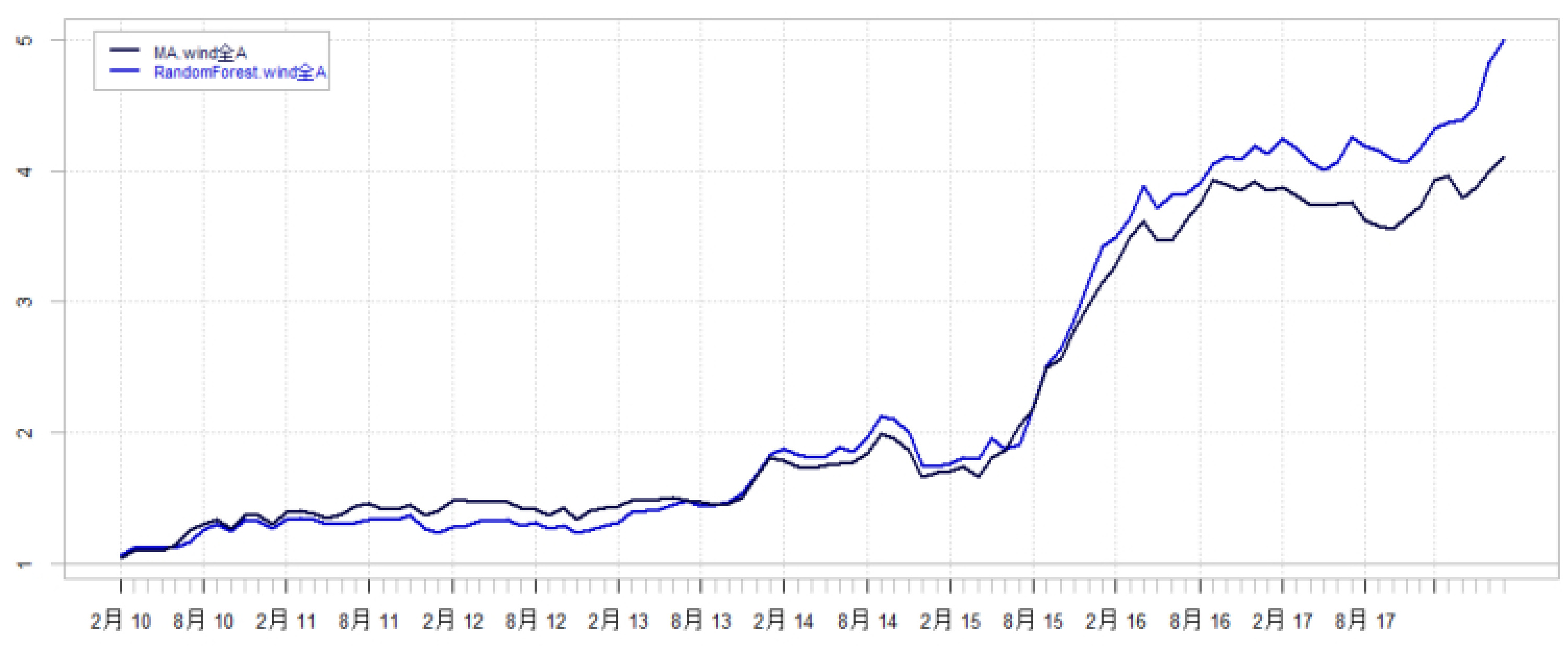
3.3 全体A股样本池
- 收益表现:
- 随机森林模型年化收益率提升3%,相对沪深300月胜率提升4%。
- 历史收益分布:
- 随机森林收益优势主要来自2013、2014及2017年风格切换。
- 2017后传统模型出现回撤,随机森林维持上涨态势。
- 图22-23显示整体趋势与观点一致。
- 因子表现:
- 全A股样本中,传统模型因子暴露波动性显著上升,且始终高于随机森林。
- 收益构成方面,传统模型主依赖市值、流动性和反转因子,随机森林依赖市值、流动性和估值因子。
- 市值因子在两模型中均为最大贡献因子之一,暗示操控市值因子风险极为重要。
- 细因子暴露图(图24-31)显示,随机森林模型成长、盈利和反转因子波动较小,而传统模型激进暴露可能导致风险。[page::17-20]
2.4 总结与未来研究方向(4.总结与未来研究方向展望)
- 随机森林模型在三个样本池内对比均表现优异,尤其是在市场风格转折期展现强大的适应性,推荐在风格不明朗时优先采用。
- 传统多因子模型因子暴露波动率大,风格极端,合并风险模型进行组合风险控制显得必要。
- 小市值股票比例提升,因子暴露及波动率均上升,需加强市值因子风险管理。
- 未来拟从以下方向完善模型:
- 采纳更多机器学习算法(Boosting、SVM、神经网络等)。
- 结合收益模型与风险模型,控制波动率。
- 优化因子预处理方法。
- 引入细分行业模型与行业轮动模型构建分层选股体系。
- 风险提示:市场环境变化存在模型失效的可能。[page::20-21]
---
3. 图表深度解读
图1:随机森林算法示意图(page 4)
- 描述:图示展示随机森林的样本与变量随机抽取方式和多决策树投票分类流程。原始数据通过bootstrap抽样产生多个随机子集,每个子集生成单棵决策树,最后通过投票法得到最终分类结果。
- 解读:图形说明随机森林利用了样本和因子多样性,能够降低过拟合且具备很强泛化能力,适合挖掘非线性复杂关系,适用股价涨跌预测。
- 联系文本:支持报告中随机森林模型灵活稳定、抗噪声的理论基础。[page::4]
---
表2-3:沪深300选股模型历史回测结果及年度划分收益(page 11)
- 表2显示随机森林模型总体收益和胜率均优于传统多因子。
- 表3细分年度表现,2013-2015年明显领先。
- 意义:验证随机森林更能捕捉风格切换期机会,提升风险调整后收益。
---
图2-3:沪深300回测收益曲线及对冲基准曲线(page 11)
- 曲线清晰显示,随机森林模型复合指数走势,突出2014年反弹期间优势。
- 对冲图进一步剔除基准收益影响,展示超额收益,随机森林优势明显。
- 意义:实证随机森林模型更快捕捉市场变化,风险控制较好。
---
表4 & 图4-11:沪深300因子统计与因子历史暴露趋势(page 12-13)
- 表4显示传统模型因子暴露波动率为随机森林近两倍,且动量反转因子收益分布有差异。
- 图4-11展示了主要因子在时间序列的暴露变化状况,两模型虽趋势相似,传统模型波动性大。
- 意义:传统模型偏激进,选股风险较大;随机森林风格更为稳定。
---
表5-7 & 图12-21:中证500对应统计(15-17页)
- 与沪深300类似,随机森林模型减少了波动率,提升胜率。
- 2014、2017年风格变动遭遇明晰,随机森林赢得更多超额收益。
- 因子暴露方面,市值因子过大负暴露导致传统模型早期表现逊色。
- 因子时间轨迹图再次体现传统模型因子暴露范围更广波动大。
---
表8-10 & 图22-31:全体A股模型表现(18-20页)
- 全体A股样本中,随机森林优势更为突出,年化收益提升3%,反映大样本池对随机森林的适应性更佳。
- 多数年度随机森林在风格切换时保持良好表现,传统模型波动更显著。
- 全A样本因子暴露增幅明显,提出对市值因子风险管理的迫切需求。
- 细因子暴露差异最大,风险偏好可能导致传统模型选股效果不佳。
- 意义:大规模样本中,随机森林采集信息能力更强,风险控制更优。
---
4. 估值分析
本报告未涉及传统意义的个股估值或整体市值评估,主要关注股票池选股模型的组合表现和因子风险收益特征,未采用DCF、P/E等指标,重点放在统计模型预测能力上的比较。
---
5. 风险因素评估
- 报告明确指出模型可能面临失效风险,尤其是在市场环境大幅变化或者因子失效时风险较大。
- 市值因子过度依赖可能导致模型回撤风险,建议加强市值因子风险敞口控制。
- 传统多因子模型因风格极端,更需要结合风险模型进行组合风险管理,降低大幅回撤概率。
- 模型预测未来市场变化依赖历史数据,未来不确定性和非历史模式可能导致预测误差。
- 风险提示明确,未提供具体缓解策略,但建议结合风险模型和行业轮动模型多元化提升稳健性。[page::0,21]
---
6. 批判性视角与细微差别
- 报告对随机森林模型的优势表达较为积极,尤其强调风格转换期的超额收益,但对其短期欠佳表现(如2010-2013年部分年度)未做深入说明,部分原因可能与样本选择及因子贡献变化相关。
- 传统多因子模型因子暴露波动大,一方面带来高收益潜力,另一方面可能带来极端风险,报告未完全论述此波动性带来的潜在机会成本。
- 随机森林模型的黑盒特性质在报告中未详细讨论,可能对模型解释性和因子理解带来挑战。
- 市值因子依赖问题贯穿全文,但具体的风险管理方案尚未提出,未来实际操作中仍需关注。
- 因子预处理与特征工程细节较少,对不同策略组合及参数敏感性探讨有限。
- 报告逻辑整体自洽,各节数据与结论保持一致,图表配合良好,无明显矛盾。
---
7. 结论性综合
该报告通过对沪深300、中证500及全体A股三个不同样本池回测,系统比较了基于随机森林机器学习算法的多因子选股模型与传统线性回归多因子模型的表现差异。核心发现包括:
- 随机森林算法表现优势明显,在所有样本下均实现了收益与月度胜率的提升,特别是在市场风格转换的关键节点(2014年、2017年)更能快速捕捉市场变化,实现超额收益。
- 因子暴露波动性是两种模型最大区别:传统多因子模型因子暴露波动率较随机森林高近两倍,风格更为极端,因子收益集中在市值与估值因子;相较之下,随机森林的因子暴露更为稳健,收益来源也更均匀,显示出更优秀的风险调整能力。
- 市值因子的风险敞口需重点控制,随着样本小市值比例增加(从沪深300到全A),因子波动和市值暴露均显著增加,提示市值因素潜在失效风险与组合风险。
- 短期因子(反转)与长期因子(动量)在两模型应用上的差异提供了对模型选股风格的深刻见解,随机森林更适合捕捉短期反转,传统模型依赖长期动量。
- 图表系统展示了回测收益曲线、基准对冲曲线及因子暴露动态,清晰直观地支持了上述分析结论。
- 报告建议结合更加多样的机器学习算法,融合风险及行业模型提升策略稳健性和精细化,进一步优化多因子选股体系。
总之,该报告以严谨的数据回测和业绩归因分析,充分论证了随机森林作为非线性机器学习工具在股票多因子选股中的应用价值及优越性,提醒了传统多因子模型在因子暴露和风险管控上的不足,并明确指出未来改进方向和潜在风险,对于量化资产管理和多因子投资策略研究具有重要参考意义。[page::0-21]
---
附:部分关键图表示意
图1 随机森林算法示意图
图2 沪深300选股模型回测收益曲线
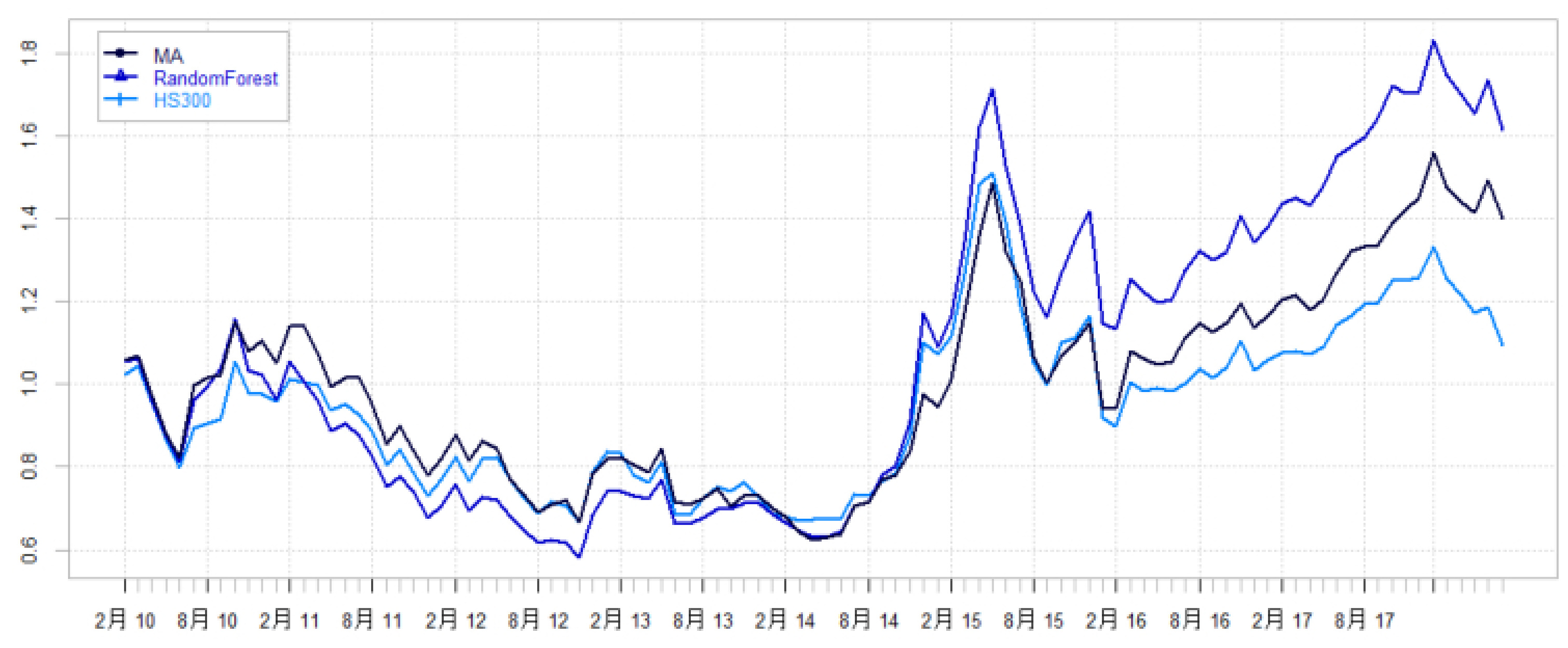
图3 沪深300选股模型对冲基准回测收益曲线
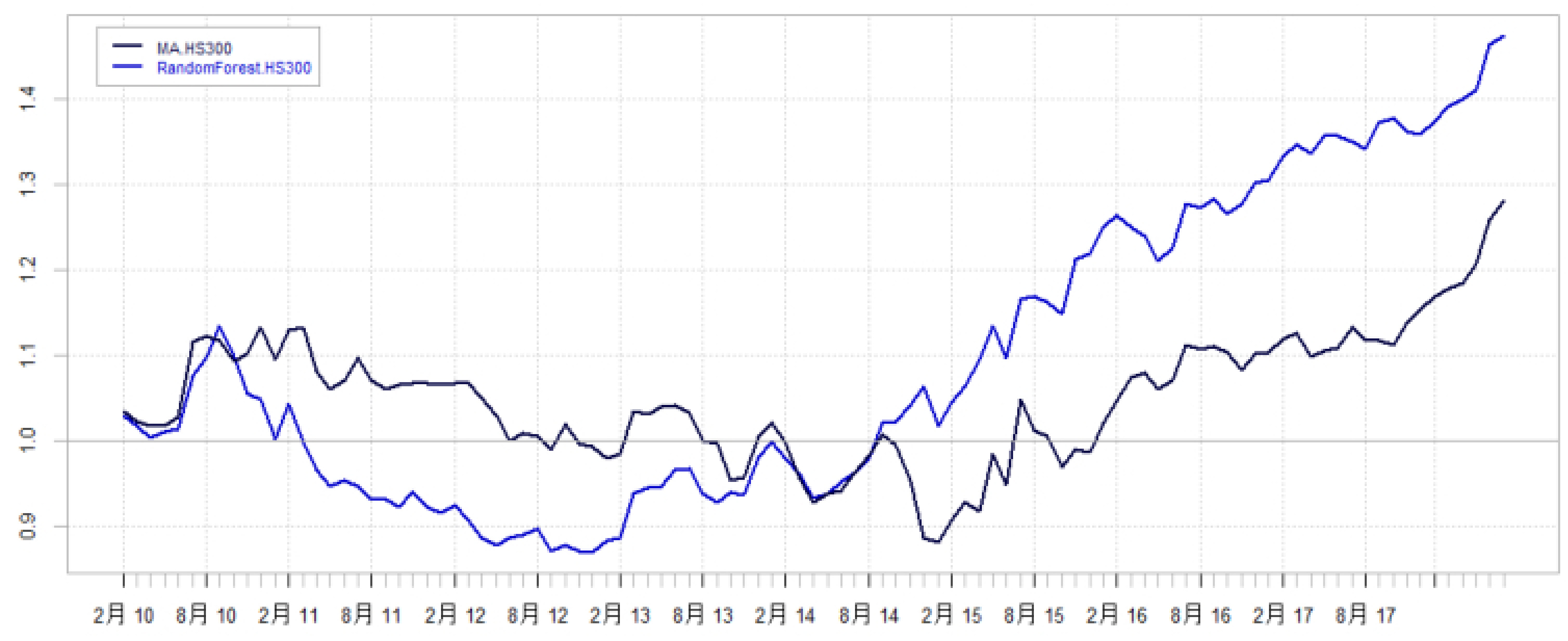
图4 沪深300选股模型市值因子历史暴露
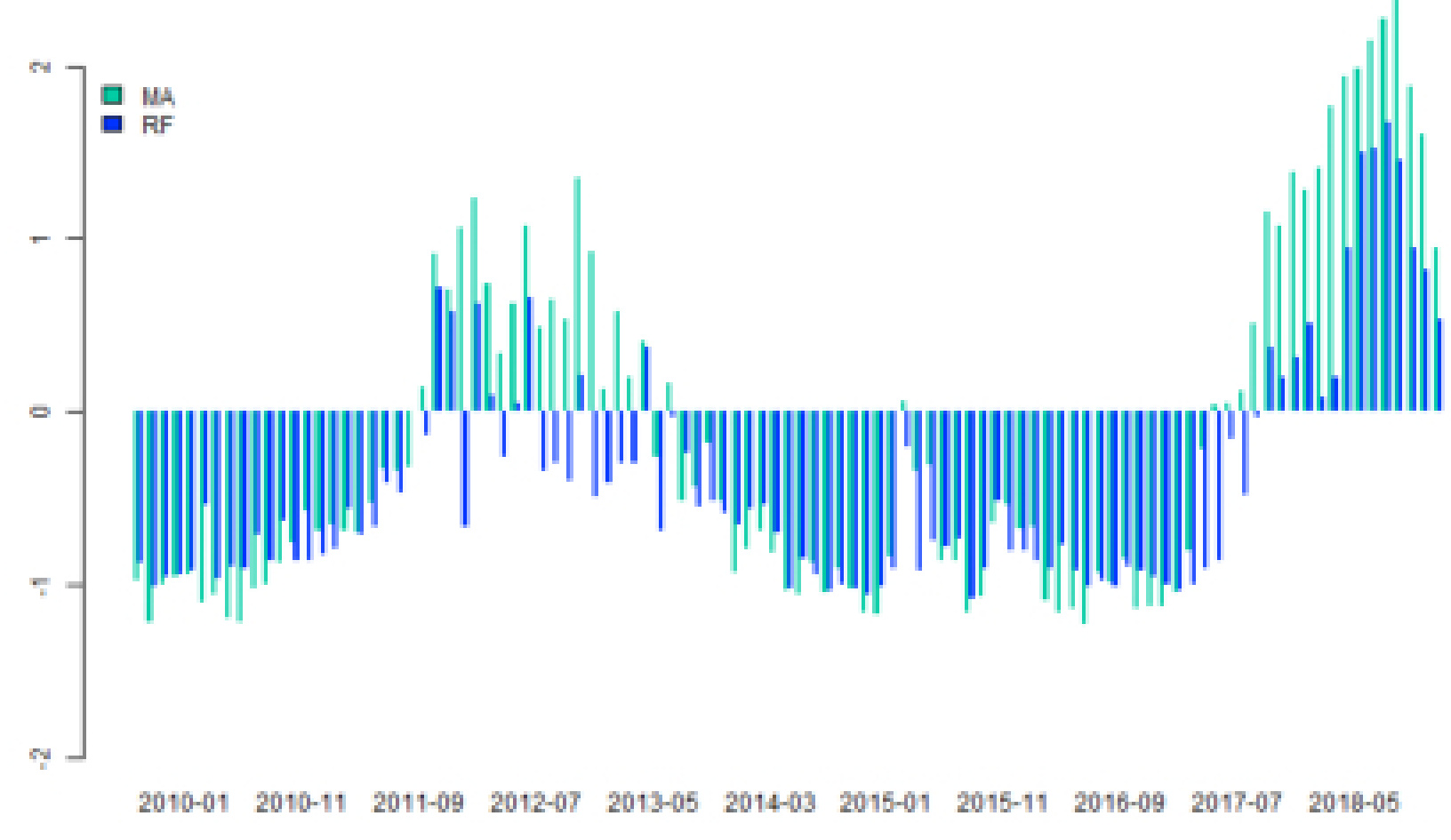
图12 中证500选股模型回测收益曲线
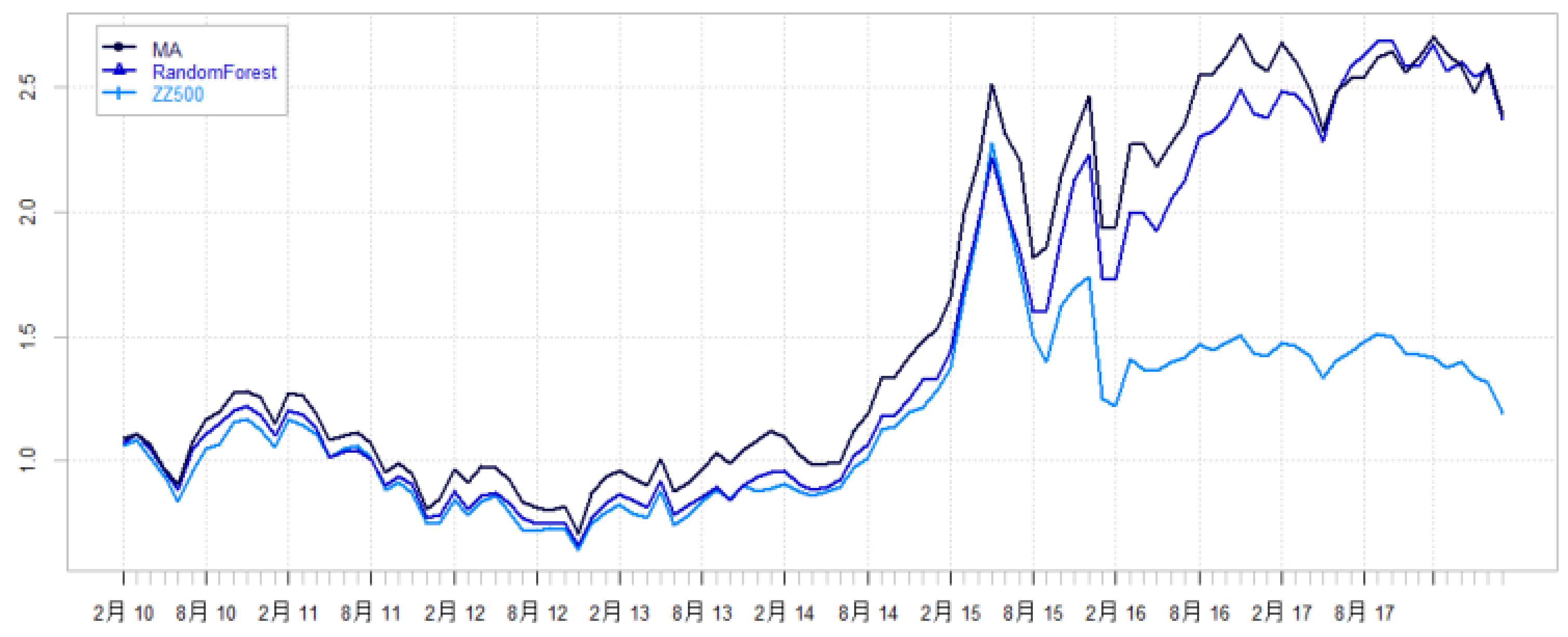
图13 中证500选股模型对冲基准回测收益曲线
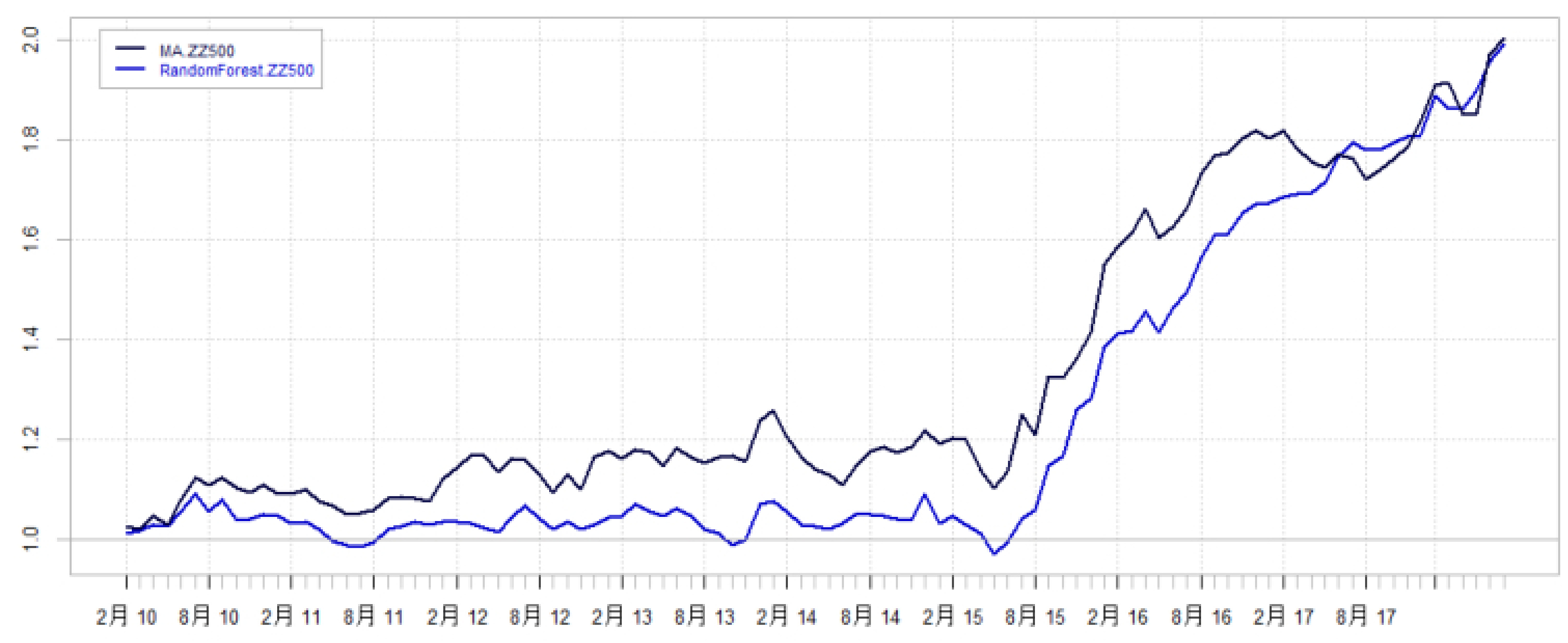
图22 全体A股选股模型回测收益曲线
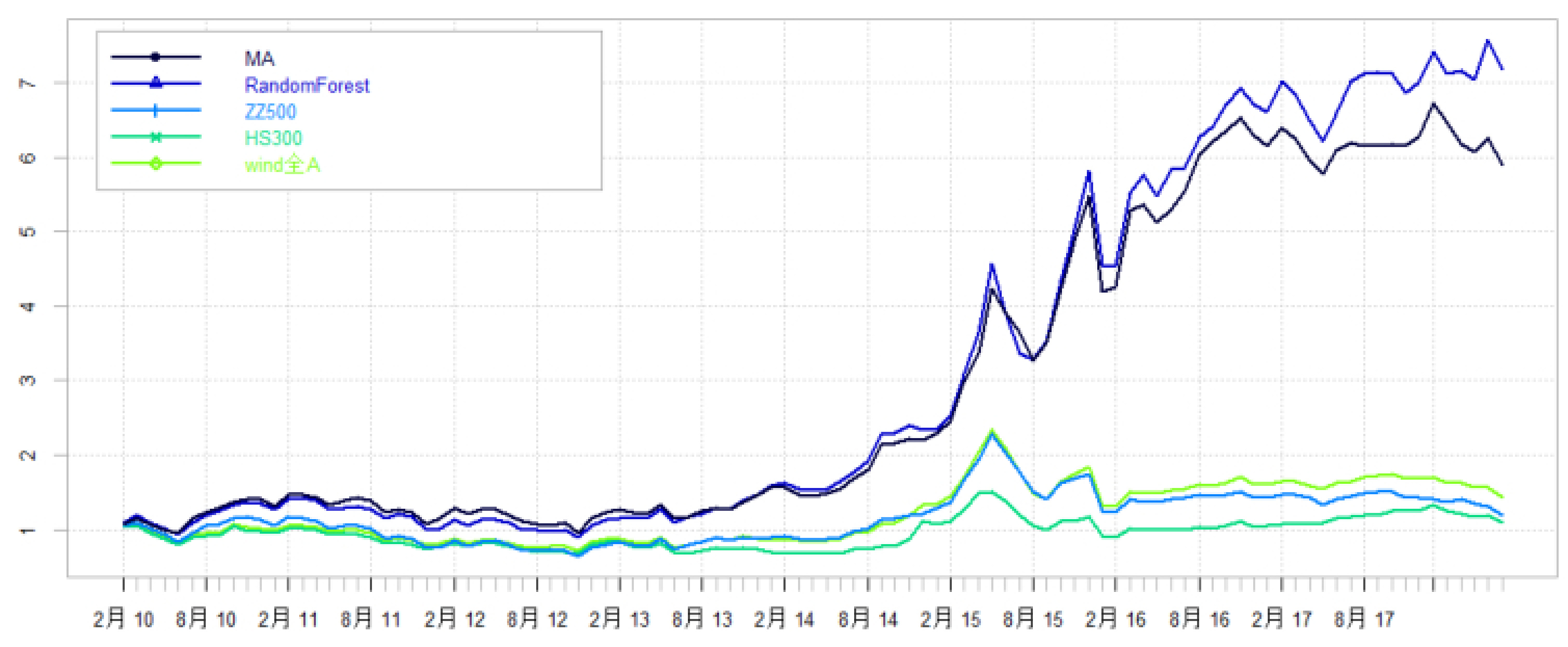
图23 全体A股选股模型对冲基准回测收益曲线
---
结语
本文报告系统地对随机森林和传统多因子模型的理论机制、建模流程、历史表现及因子暴露特征进行了多样本池、大跨度时段的全方位对比,借助细致的业绩归因分析,不仅验证了随机森林模型的柔性和优势,同时也揭示了传统模型因子风格激进易波动的弱点,为A股多因子选股模型创新提供了实证依据和未来研究指导。
---
【注】本文所有结论均严格基于报告文本和数据,文中所有内容按原文页码加注溯源标识。




