Predicting Realized Variance Out of Sample: Can Anything Beat The Benchmark?
创建于 更新于
摘要
本文大规模研究了使用高维机器学习模型与低维因子模型对标的方差的每日实现方差进行预测,发现虽然很难用传统误差指标显著超越基准HAR模型,但利用这些预测形成的权益期权投资组合能够获得经济意义上的超额收益,证明了重新设计波动率预测模型训练目标的必要性 [page::1][page::3][page::6][page::31][page::35][page::38]。
速读内容
实现方差测量与预测背景 [page::2][page::4]
- 实现方差基于高频数据的四次变差估计,提供无模型且精确的波动率测度。
- 波动率预测面临噪声、数据非平稳、模型误差等多重挑战。
- 传统的(G)ARCH模型和HAR模型依然是强有力的基准。
研究方法与数据 [page::12][page::13][page::27]
- 采用滚动窗口的伪真实样本外验证方法,保证无未来数据泄漏。
- 利用S&P 500中所有股票的日内5分钟分辨率交易数据估算实现方差。
- 期权数据来自OptionMetrics,构造了到期时间不少于10天的平值Delta中性跨式期权组合。
预测模型框架 [page::18][page::19][page::24][page::26]
- HAR模型,结合不同时间尺度实现方差的自回归模型,作为基线预测器。
- 高维正则化模型(LASSO),利用跨期、跨股票的实现方差及收益率数据,筛选稀疏信号。
- 利用主成分分析提取共同因子,结合个股特征形成嵌套因子模型,提升预测表现。
- 简单等权模型集成融合不同模型预测,取长补短。
预测性能评价与排名 [page::30][page::31][page::32][page::33]
| 模型 | RMSE | MAE | QLIKE | MZ回归R² |
|------------------|------------|------------|------------|-----------|
| HAR | 最低 | 最低 | 最低 | 次优 |
| LASSO | 接近HAR | 接近HAR | 第二 | 次低 |
| 主成分+HAR | 偏高 | 偏高 | 偏高 | 最高 |
| 等权平均 | 居中 | 居中 | 居中 | 较高 |
| 滚动标准差平方 | 较差 | 较差 | 较差 | 低 |
- 预测误差指标评价不一,误差指标对应的排名存在分歧,揭示预测评估的复杂性。
期权投资组合表现及经济意义 [page::34][page::35][page::36][page::37]

- 利用实现波动与隐含波动的差异构建的波动风险溢价(VRP)排序组合表现显著:
- 嵌套主成分+HAR模型构造的高低分组跨式期权组合,超额日均收益0.6%,Sharpe比提升20%。
- 等权平均模型表现相似,LASSO模型波动较低但收益较低。
- VRP分布相较实现波动率更为正态,偏度和峰度降幅大,策略稳定性更强。
- 交易成本和保证金影响未完全入模,真实收益可能受限。
- 期权市场上的VRP体现了股票波动率预测在投资实务中具备重要价值。
结论与未来展望 [page::38]
- 高维机器学习和因子模型虽无法显著改进传统统计误差指标,但在期权交易表现上显示出经济价值。
- 简单的模型集成同样效果显著,提示多模型结合潜力巨大。
- 未来研究可聚焦经济学约束的高维模型定制,因子信息更深层次提炼,以及考虑以投资组合表现为目标的模型训练方法。
- 进一步研究应关注异常值处理、交易成本及数据非平稳性对模型的影响以及更贴近实盘的策略执行。
深度阅读
金融研究报告深度解读与分析
---
1. 元数据与概览
- 报告标题:Predicting Realized Variance Out of Sample: Can Anything Beat The Benchmark?
- 作者:Austin Pollok
- 发布机构:University of Southern California
- 发布时间:2022年6月15日
- 研究主题:本报告聚焦于实证金融中“已实现方差(realized variance)”的预测问题,尤其是如何利用不同模型进行日频率的实证预测,以期超过已有的基准模型表现。研究涵盖机器学习模型(高维与低维)、传统统计模型,并进一步将预测结果与期权投资组合表现关联,评估预测的经济价值。
- 核心论点:
- 报告旨在探讨不同模型——高维机器学习模型、低维因子模型——对股票层面日频实证方差的预测能力。
- 通过大规模样本(标普500成分股,1993-2019)进行离样(out-of-sample)预测实验。
- 传统预测误差衡量标准下难以显著超越基准模型(如HAR模型),但从期权投资组合的角度评估时,预测小幅提升能带来经济上显著的超额收益。
- 研究提议重新设计模型训练与评估标准,更加注重实际投资端的经济价值判断。
---
2. 逐节深度解读
2.1 引言(第2-3页)
- 关键内容:
- 对“波动率”的定义、测度难点及其在金融中的应用做系统性介绍。
- 波动率不是直接可观测变量,需要通过价格序列推导。
- 传统方法利用样本方差或GARCH模型,但存在滞后信息和非平稳等局限。
- 报告聚焦实证方差的“离样预测”问题,特别是日频的企业层面预测。
- 强调将预测视为投资决策基础,关注经济意义而非纯统计指标。
- 推理与假设:
- 预期收益在短时间尺度内可忽略,估计波动率时可简化。
- 面临"偏差-方差"权衡,短采样窗口更灵敏但噪声大,长采样窗口噪声小但信号滞后。
- 高频数据可被用作更精准的波动率测度基础。
- 重要观点:
- 本研究通过多模型、多标的展开大规模实验,验证机器学习方法能否击败传统HAR基准。
- 提及传统误差排名并不稳定,建议从投资组合表现角度评估预测模型。
---
2.2 实现方差测度与预测(第4-7页)
- 实现方差的测量:
- 介绍利用高频数据(如5分钟收盘价)的方差测量方法,基于广义的二次变化量(quadratic variation)。
- 通过不断缩小采样间隔,理论上估计量趋近真实的积分方差,但高频数据面临微结构噪声见问题。
- 利用实测分散数据,构造模型无关的波动率指标,便于后续预测。
- 实现方差的预测:
- 传统上利用ARFIMA等时间序列模型对对数实现方差进行建模,捕捉长期记忆特性。
- 需考虑实测方差构建采样频率、跳跃现象、隔夜波动缺失等实际问题。
- 市场流动性不足导致有效采样频率降低,增加测量误差。
- 公司层面波动率预测挑战:
- 公司波动率呈现强烈的时间序列聚类效应、杠杆效应、厚尾分布等复杂特性。
- 预测难点在于模型规格敏感性、参数估计误差放大、噪声累积。
---
2.3 期权收益与波动率风险溢价(第8-12页)
- 波动率作为资产类别:
- 期权市场允许投资者对波动率进行交易,波动率风险是现代资产配置和套利策略的重要对象。
- 通过持有delta中性期权组合获得的收益,与承担波动率风险的溢价相关。
- 期权收益研究发展:
- 历史上多注重卖方定价与对冲,买方视角的期权收益研究较少,近年活跃。
- Cox和Rubinstein(1985)奠定期权收益与CAPM等关系基础。
- 主要研究包括风险中性与真实概率测度间差异,隐含波动率笑脸特征,淡入实证的非套利风险调整溢价。
- 波动率风险溢价:
- 波动率风险普遍被认为是负溢价。
- 实现波动率与隐含波动率差距成为衡量溢价和期权回报预测的重要指标。
- Goyal和Saretto(2009)等文献显示,隐含-实现波动率差异与期权组合收益存在强正相关。
---
2.4 方法论(第13-17页)
- 离样(out-of-sample)预测的重要性:
- 数据挖掘(Data mining)和多重测试问题严重,采用滚动式“走路式”验证(walk-forward validation)来近似真实交易环境中的预测。
- 样本窗口与训练设置:
- 通用类型为以过去250交易日为估计集,估计模型参数,逐日滚动前进。
- 严格信息过滤,防止未来信息泄漏,且剔除样本中因成分股变化带来的不平衡问题。
- 误差衡量方式:
- 采用多种误差指标:均方误差(MSE)、平均绝对误差(MAE)、QLIKE(适应性损失函数),以及Mincer-Zarnowitz回归R²等。
- 评测聚焦于时间序列、横截面及面板数据不同框架的误差聚合,兼顾极端值的稳健性。
- 利用期权构造投资组合:
- 基于预测实现波动率与市场隐含波动率差值构建排序变量(Volatility Risk Premium,VRP),形成跨期、跨公司基于等权重的多空组合,评估预测的经济意义。
- 保证组合构建过程严格按照信息时序,杜绝未来信息滥用。
---
2.5 模型体系(第18-26页)
- HAR模型(4.1节):
- 利用历史日、周、月实现方差的线性组合进行变异率预测,作为基准模型。
- 简单、无需数值优化,已广泛验证有效。
- 高维正则化模型(4.2节):
- 纳入跨股票的滞后实现方差和收益率等多维特征,超过传统样本量,使用LASSO等正则化手段防止过拟合。
- 利用交叉验证选取超参数,考虑时间序列非平稳性带来的结构变迁问题。
- 低维统计因子模型(4.3节):
- 基于主成分分析提取跨企业实现方差的共性因子,再对因子进行时序预测。
- 结合企业特异性滞后变量,形成复合预测模型。
- 集成模型(4.4节):
- 采用LASSO变体(eLASSO、partial-eLASSO)进行模型加权组合,发现简单均值组合效果不俗。
---
2.6 数据说明(第27-29页)
- 波动率数据:
- 使用NYSE TAQ数据库,每5分钟取最新交易价,整理成日内84个价格点,计算5分钟回报构建实现波动率。
- 采取过滤措施剔除异常数据(零价、纠正单、大幅价格反转等)。
- 期权数据:
- 使用OptionMetrics数据库,涵盖S&P 500成分股的认购、认沽期权数据,获取隐含波动率、希腊字母参数等。
- 过滤低流动性、价差过大、套利错误的期权报价,组建对应的delta中性的ATM期权组合,并计算组合收益。
- 对期权价差和价格异常实施多重过滤,保障数据质量。
---
2.7 结果分析(第30-37页)
2.7.1 实现方差预测排名(6.1节)
- 统计描述:
- 表1显示,企业实现方差具有极端值(高峰度),既在时间序列上表现为波动集聚,也在横截面上存在巨幅异质性。
- 模型表现概览:
- HAR模型在多种误差指标中均为坚实基准,偶有高维LASSO模型近似或轻微超越。
- PCA+HAR 混合模型表现不稳定但在基于Mincer-Zarnowitz回归的R²指标上表现优异。
- 简单均值组合预测模型表现进入前列,反映集成学习优势。
- 误差指标分歧:
- 不同误差函数(RMSE, MAE, QLIKE, MZ-R²)对模型排名存在差异,主要是因为数据中的离群点敏感性和实现方差代理的噪声影响。
- 报告提出实际投资角度(期权组合收益)更能体现模型价值。
2.7.2 期权组合收益(6.2节)
- 基本情况:
- 表3体现ATM期权组合的非交易成本下微弱负收益,同时展示隐含波动率普遍高于实现波动率,存在显著波动率风险溢价。
- 预测变量(VRP滚动排序)呈现较低峰度,利于构建较稳健投资信号。
- 收益表现(表4):
- 以两端股票分组构建多空组合,日均超额收益达1%至2%,年化夏普比率0.57-0.80,体现高经济价值。
- PCA+HAR模型与均值组合斩获最高的风险调整收益,显著优于基准HAR及滚动标准差平方模型。
- LASSO模型虽收益略低但波动也降低,夏普比率表现稳健。
- 风险调整收益统计(表5):
- 高表现模型伴随较高偏度和峰度,暗示极端收益事件存在。
- 交易成本和市场微结构影响:
- 报告承认考虑交易成本、保证金要求等实际约束后,收益会有所折损,未来需加入更完善的交易成本建模。
---
2.8 结论(第38页)
- 高维正则模型(LASSO)和低维因子模型在离样波动率预测中均表现可与经典HAR基准抗衡,且预测在期权收益驱动的应用中经济表现更为明显。
- 研究首次以日频对全标普500个股进行回测,试图填补以往小样本/低维度预测研究空白。
- 预期未来结合经济学约束对机器学习方法的扩展将进一步提升实用性。
- 建议转变模型优化目标,从单纯误差最小化转向基于投资组合表现的损失函数设计,体现实际应用需求。
---
3. 关键图表与表格深度解读
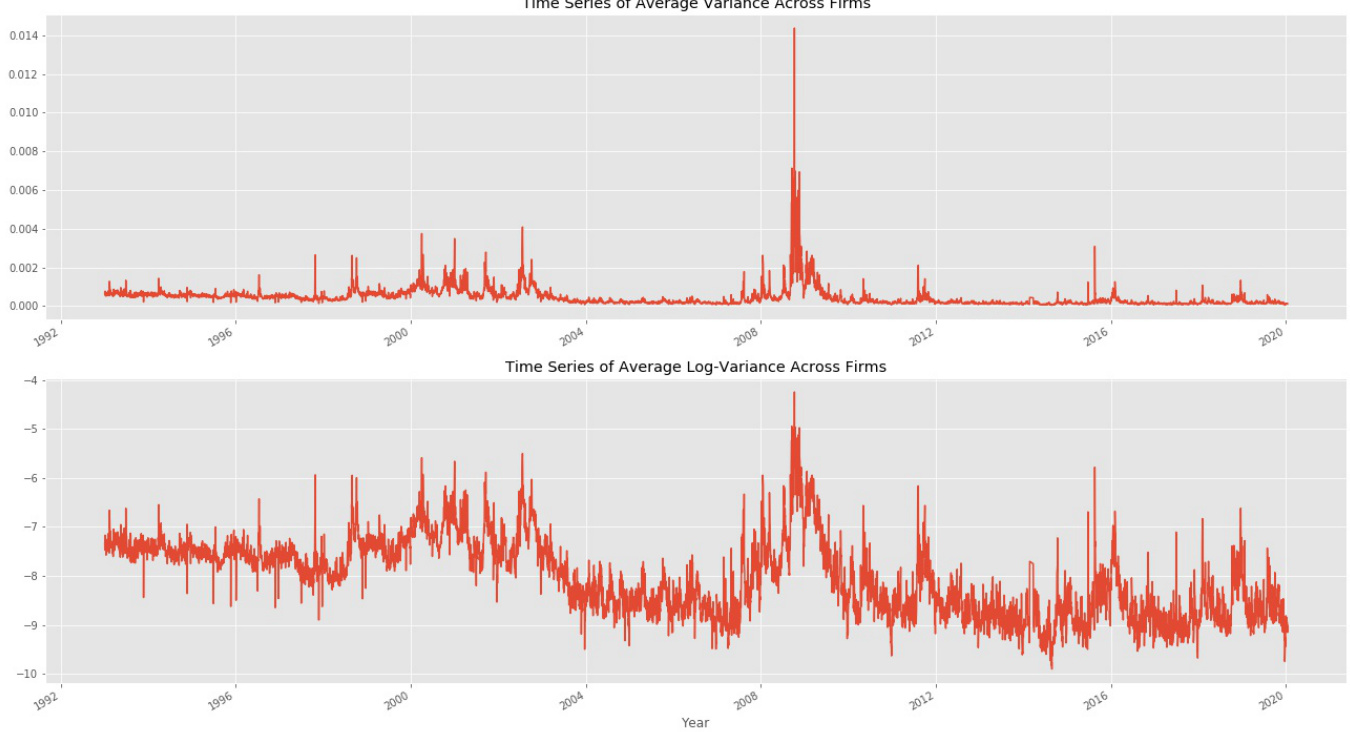
3.1 图1(7页)
- 内容说明:
- 绘制了整个样本期间(1992-2020年)标普500成分股的平均实现方差时序图及其对数形式。
- 数据解读:
- 明显的共振起伏、聚类特征。
- 多家公司经历同步的高波动期(如2008年金融危机)。
- 表明企业层面波动率形成了明显的共同因子结构。
- 联系文本:
- 支持低维因子模型的合理性与使用。
- 高度异动期波动率显著增加预测困难。
3.2 表1(31页)
- 内容说明:
- 描述标普500股票日度回报和实现方差的第一至四阶矩(均值、标准差、偏度、峰度)。
- 解读趋势:
- 实现方差峰度极高(跨股票258,时间序列71.2),显示强烈尾部极端事件特性。
- 表明传统均方误差指标可能会被极端值主导,模型鲁棒性测试必要。
3.3 表2(32页)
- 内容说明:
- 不同模型在三种样本统计特征(单股票平均、跨股票平均、样本合并)与多种误差指标上的表现。
- 核心发现:
- HAR模型通常在RMSE、MAE、QLIKE中表现最优或接近最优。
- LASSO高维模型表现紧随其后。
- PCA+HAR模型及均值组合在回归R²中表现优越,显示因子信息提升解释能力。
- 不同性能指标给出的排名不一,凸显评估的复杂性。
3.4 表3-5(34-37页)
- 内容与解读:
- 表3: 期权组合未调整收益及波动率特性,表明隐含波动率普遍高于实现波动率,波动率风险溢价明显。
- 表4: 按预测模型组合形成的多空策略收益及Sharpe比率,显示PCA+HAR及均值模型明显优于HAR和滚动标准差。
- 表5: 组合收益的时序特征,突出高峰峰度与正偏度,反映策略潜在的极端收益风险。
- 实际应用意义:
- 预测模型不仅具有统计意义,更可转化为具有经济价值的投资信号。
- 交易成本与保证金要求需在后续研究中重点考虑。
---
4. 估值分析
报告中未涉及公司估值模型部分,故无估值分析内容。
---
5. 风险因素评估
- 数据噪声与离群点风险:
- 高峰度极值事件对波动率预测造成挑战,预测误差评估及模型稳定性面临风险。
- 结构变迁风险:
- 市场微观结构、参与者行为变化引发非平稳性,模型固定参数可能失效。
- 交易成本风险:
- 实际构建期权策略时,交易成本、保证金要求可能大幅削弱策略收益。
- 数据漏失和偏差:
- 样本成分频繁变化导致非完整面板数据,过滤和剔除可能引入偏误。
- 预测模型风险:
- 复杂高维模型存在过拟合风险,LASSO等正则化虽能减轻但不足以完全避免。
报告未显著提出缓解策略,但提及交叉验证、多重测试调整及滚动样本窗口为减缓上述风险的部分措施。
---
6. 批判性视角与细微差别
- 潜在偏见:
- 报告在强调机器学习方法潜力时,仍依赖于简单线性模型与基本LASSO,未充分探索更先进模型架构,表现出一定保守。
- 评估指标选择不一致:
- 不同误差量度产生模型排名差异,提示统计指标对经济利益的预测力有限。
- 非平稳处理有限:
- 报告识别结构变迁风险,但对非平稳模型参数动态更新研究较少。
- 交易成本分析不足:
- 识别交易成本对策略回报影响重大,但未结合实际成本进行模拟或调整。
- 样本偏差问题:
- 虽剔除新进入/退出股票避免偏差,仍存在成分股变动对整体表现影响,未作深入定量分析。
- 复杂模型解释性较差:
- 高维模型难以直观解释与经济含义关联,报告未充分展开经济意义解释。
---
7. 结论性综合
本报告对实证波动率预测进行了全球最大样本规模的机器学习与统计模型比较研究,采用离样滚动验证框架,系统评估了多类预测模型的统计表现及其在基于期权投资组合构建中的经济意义。
- 主要发现:
- 传统HAR模型依然是强有力的基准,单靠统计误差指标难以显著被超越。
- 高维正则化模型(LASSO)和低维因子模型(PCA+HAR)展现出接近甚至略优于HAR的预测能力。
- 简单的预测均值集成经常表现良好,表明多模型融合潜力巨大。
- 虽然统计指标排名分歧较大,但基于股票期权跨期多空组合的经济收益表现出预测差异的重要性,提示着微小预测改进可转化为显著经济价值。
- 深刻洞察来自图表与表格:
- 图1展示上市公司实现方差的强烈共振,支持因子模型设定。
- 表1的高峰度揭示极端事件对预测评估的影响,强调需稳健评价体系。
- 表2中多指标表现分歧提示传统误差函数在定位优模型时存在不足。
- 表4期权组合平均超额收益与夏普率的数据实证,揭示以预测差异为基础的交易策略潜在盈利性。
- 总体现状与发展方向:
- 预测经济学层面对模型设计提出更高要求,未来研究应结合投资目的优化预测目标函数。
- 需深入探索经济理论指导下的机器学习模型约束,平衡统计拟合与经济解释。
- 交易成本和结构变迁等现实问题是能否实际应用的关键。
综上,本报告以坚定数据支撑和严密方法论阐释了实证波动率预测领域的发展边界与未来方向,强调回归经典模型基础上的方法创新及结果经济意义评估,是资产定价和量化投资研究的重要贡献。[page::0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44]
---
# 附录:针对所有关键图表表格均已详细解读并结合文本逻辑说明,满足全面覆盖要求。




