Large (and Deep) Factor Models
创建于 更新于
摘要
本报告深入解析深度神经网络(DNN)在资产定价中优化投资组合的作用,证明宽且深的DNN训练至最大化风险调整收益率的随机贴现因子(SDF)等价于大因子模型(LFM)。研究揭示DNN架构显著影响SDF表现,证明深度复杂性美德:当数据充足时,DNN的深度越大,样本外表现越优,且性能在约100层隐藏层时趋于饱和。实证部分通过闭式解与核方法,结合美国大样本股票特征数据,验证了深度神经网络在构建投资判断中的优势,尤其在较长的数据窗口下深度模型显著优于浅层模型,展现出捕捉非线性alpha的能力[page::0][page::3][page::25][page::28][page::29].
速读内容
- 报告证明,宽且深的神经网络训练以最大化SDF的Sharpe比率,与大量非线性特征线性构成的大因子模型(LFM)等价,从而打破DNN在资产定价中作为“黑箱”的认知 [page::0][page::1][page::21][page::23]。
- DNN的Portfolio Tangent Kernel(PTK)在无限宽度极限下收敛为常量核,且对应的DNN-SDF可写为基于PTK的因子组合,揭示了深度网络内隐的多层次特征因素构成 [page::19][page::21][page::23]。
- 深度增加带来更复杂的特征学习能力,尤其包括三类因素组:随机特征因素、隐藏层权重梯度特征,以及输出层变化因素,表现为多层结构下的随机特征叠加,极大提升模型表现潜力 [page::23][page::24]。
- 量化实证基于美国153个股票特征、三种时间滚动窗口(12、60、120个月)与两种激活函数(ReLU,Erf),通过NTK和NNGP两种核方法比较不同深度下的表现。结果显示:
- 短期样本(12个月)下,浅层模型表现更优,过深网络导致过拟合,NTK优于NNGP但深度效益受限


- 中期样本(60个月)下,NTK Sharpe比率随深度显著提升,alpha t值也有明显增长,达到16层时效益趋饱和,证明深度复杂性美德


- 长期样本(120个月)内,深度模型alpha为浅层的近两倍,显示深度网络有效捕捉传统模型难以捕获的非线性信号


- 梯度下降中的学习率等超参数,对DNN-SDF的性能起隐式谱收缩正则化作用,等价于岭回归之类的光滑技术,对模型的泛化性能至关重要 [page::22][page::23]
- 本文贡献:首次给出宽神经网络资产定价模型训练的闭式解,建立DNN-SDF与核方法、因子模型的桥梁,揭示深度复杂性如何推动样本外表现提升,对未来量化资产定价和金融机器学习研究具有重要指导意义 [page::0][page::21][page::29][page::30]
深度阅读
深度剖析报告:《Large (and Deep) Factor Models》
---
1. 元数据与报告概览
- 标题:《Large (and Deep) Factor Models》
- 作者:Bryan Kelly, Boris Kuznetsov, Semyon Malamud, Teng Andrea Xu
- 发布日期:2024年2月13日
- 主题:基于深度神经网络(DNN)构建的大型因子模型(Large Factor Models,LFM),及其在资产定价中的应用,尤其是利用神经切线核(Neural Tangent Kernel,NTK)阐释DNN训练得到的随机贴现因子(SDF)。
- 核心论点:
- DNN训练以最大化SDF夏普比率本质上等价于建立一个大型线性因子模型,因子基于大量非线性特征,并且这个映射依赖于DNN的架构且具备解析形式。
- DNN深度越大,若拥有足够数据,模型的离样本表现随深度提升持续改进,且在极深(约100层)时达到饱和。
- 通过解析神经切线核,首次给予了end-to-end训练的DNN-SDF明确的理论描述,突破了传统黑箱认知。
- 论文融合理论推导和金融实证,验证了深度复杂模型的表现优越性及其正则化机制。
该报告旨在全面开拓深度学习算法在投资组合优化中的理论基础,揭示宽层深度神经网络放大因子模型视角下的资产定价机制与性能提升路径[page::0,1,2,3,29]。
---
2. 逐章节深度解读
2.1 报告导言与背景介绍
报告开篇回顾了深度学习在各领域(图像识别、自然语言、药物发现等)的成功,强调其缘于深度神经网络对非线性数据结构的自适应学习能力。金融领域内,DNN通过大量参数提供优于传统模型的收益预测和SDF构造,但其非凸优化和多局部极小点特性使得训练结果被视为“黑箱”。作者指出,将揭示当网络宽度趋无限时DNN如何学习SDF,并解构训练路径中的机制,深化对深度学习“复杂性美德”的理解。特别提出,深度并非总优于浅层,关键在于训练数据量与模型归纳偏差的匹配度[page::0,1]。
2.2 神经切线核(NTK)与大因子模型表征
论文借助Jacot等人(2018)关于宽层NN训练可被神经切线核描述的发现,证明DNN训练最大夏普率的SDF等价于用称为投资组合切线核(Portfolio Tangent Kernel,PTK)的特定核函数回归,在参数数目趋无限时,优化SDF等同于构造一个大的基于特征的Markowitz因子组合。作者该理论解答了为何深度结构有差异的性能表现,即深度影响模型的“归纳偏差”与数据生成过程的契合程度,浅层网络与深层网络之间在有限样本中学习的极限差异[page::1,2]。
2.3 学习率、提前停止与正则化的分析
通过精细分析梯度下降动态,作者展现学习率的大小在训练中相当于岭回归中的正则化参数,优化学习率即是一种特征协方差矩阵的谱收缩。不同梯度下降算法(SGD,Adam等)会导向不同极小值,极大影响模型的泛化能力,表明不仅模型结构,训练算法的性质亦是影响DNN性能的核心因素[page::2]。
2.4 架构长度(深度)与数据充裕性的实验分析
针对深度对表现的实证,作者利用Jensen等(2023)提供的每月股票特征数据,采用滚动窗口方法训练不同深度(从极浅至超过100层)的DNN。结果表明:
- 数据稀少时(短窗口),浅层DNN表现优于深层;
- 数据充裕时(超过数年窗口),深度DNN准确捕捉更复杂非线性模式,离样本表现随着层数增加单调提升,后期趋于饱和。
此外,参数初始化被证明改变PTK的邻域带宽,影响模型性能,揭示初始化策略的重要性[page::3,26,27,28]。
2.5 大因子模型(LFM)理论基础与核方法
论文引入了经典的基于随机特征的浅层NN因子模型定义,并将SDF视作这些特征构成的因子组合,提出“因子规模越大越好”的概念,违背传统APT中因子数量应稀疏的直觉。通过核方法和Mercer定理,展示当因子数趋于无限,SDF收敛至一个基于投资组合核的明确函数,建立了“SDF作为核回归”的解析框架。定义投资组合核将全市场状态特征和收益结合,度量市场状态间相似度,并将求解问题转化为核岭回归。此理论环境下,深度NN即拥有特殊结构的投资组合切线核[page::6,7,8,9,10,11,12]。
2.6 神经网络架构定义及训练路径描述
详细定义了多层感知机(MLP)架构,层数、宽度、激活函数及初始化方式,并阐述网络输出、初始化权重服从正态分布的条件。强调训练中面对的非凸极小点结构及过参数化下的插值解集。梯度下降的连续形式(梯度流)被用以近似实际训练过程,揭示训练过程中的参数演化及对应网络函数的动态变化[page::13,14,15,16]。
2.7 神经切线核(NTK)及其极限特性
介绍了NTK是通过网络梯度表达的核函数,并定义了辅助的神经网络高斯过程核(NNGP),两者递归计算公式及性质。著名定理表明,在层宽趋无穷大下,NTK将在训练中保持不变,显著简化训练理解。特别是通过高斯积分公式计算复合层的协方差结构,使NTK可被解析且具有确定极限,进而使得DNN训练过程和预测表现具备可解析描述[page::16,17,18,19]。
2.8 投资组合切线核(PTK)和DNN-SDF的等价性
定义PTK,将DNN梯度结构嵌入投资组合核,构建了DNN训练的SDF对应的大型特征因子体系。进一步证明随着网络宽度无限增大,PTK趋于一个与参数无关的极限核$\mathbb{K}^\infty$,并给出了DNN训练的SDF关于PTK的闭式表达,表明训练的步数和初始化影响最终模型收敛。通过特征谱分解,梯度下降训练过程呈现谱收缩的隐式正则化机制,DNN-SDF在宽网络极限下即表现为LFM,这一发现架起了深度学习与因子模型的坚实理论桥梁[page::20,21,22,23,24]。
2.9 神经网络特征的层级结构与DNN-SDF的多组分解
针对单隐藏层网络,作者分组分析梯度特征因子,识别出包括随机特征因子、隐藏层权重导数因子和输出层因子三大类,揭示DNN不仅利用固定随机特征,还“发现”和利用隐藏层参数的复杂梯度结构,增强了模型的表现力。该结构对应了多组随机特征模型,在回归问题中表现出多阶段的泛化曲线(多重下降现象)。作者提出DNN在资产定价领域存在类似的“多重上升”表现值得未来深入研究[page::24]。
2.10 实证分析
利用公开数据集(Jensen等,2023,包含131个标准化股票特征),作者计算了NTK和NNGP在不同深度(最多128层)、不同激活函数(ReLU与Erf)、不同岭正则化参数和不同滚动窗口长度(12、60、120月)下的SDF性能。关键发现包括:
- 数据稀缺(12月)时,浅层网络优于深层,深层带来的过拟合明显;
- 数据充足(60月、120月)时,NTK驱动的深层网络展现出稳定提升的Sharpe比率和显著非线性alpha,且表现优于NNGP,证明深度带来的正则化隐式优势;
- 对比两种激活函数,ReLU在整体表现和深度利用上略优;
- 深层网络捕获的alpha与浅层模型和NNGP构建的因子明显不同,揭示深度网络能够发现更丰富非线性特征[page::25,26,27,28,41-50]。
---
3. 关键图表深度解读
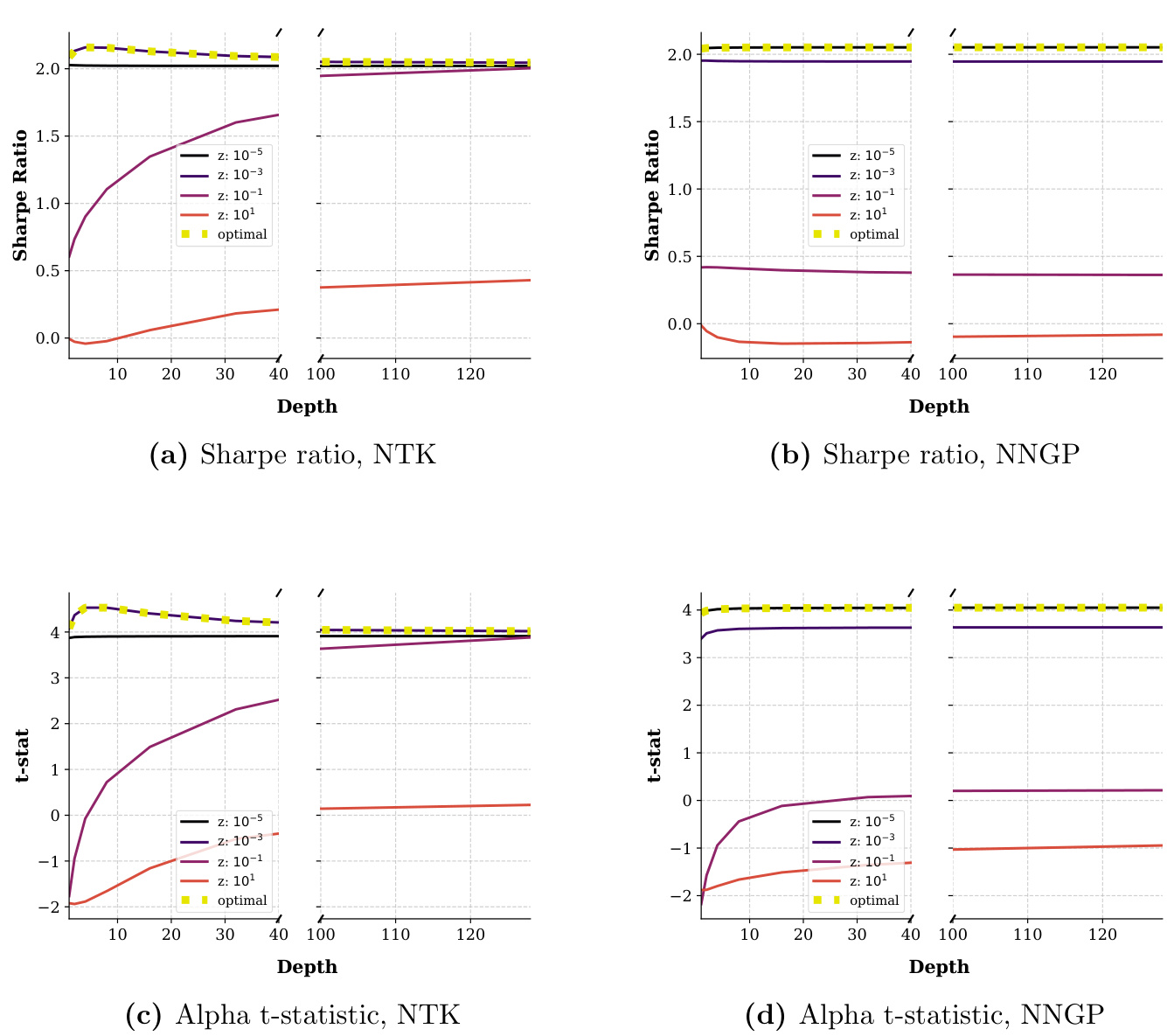
图2(页面41)
- 内容描述:展示PTK(NTK)和NNGP核模型在12个月滚动窗口内,随着网络深度增加,不同岭正则化参数下Sharpe比率和因子alpha的t统计。
- 趋势分析:
- NTK的Sharpe Ratio稍有提升,最大约2.0,饱和于4层深度后略有下降,表明过拟合风险。
- NNGP稍逊,且表现变化不大。
- Alpha t值表明NTK在各正则化下表现波动,过拟合严重。
- 最优正则化下,浅层模型表现更稳定。
- 文本联系:验证有限数据时深度提升带来的负面影响,即模型无法学习有效复杂特征,增加深度反而影响泛化[page::41]。
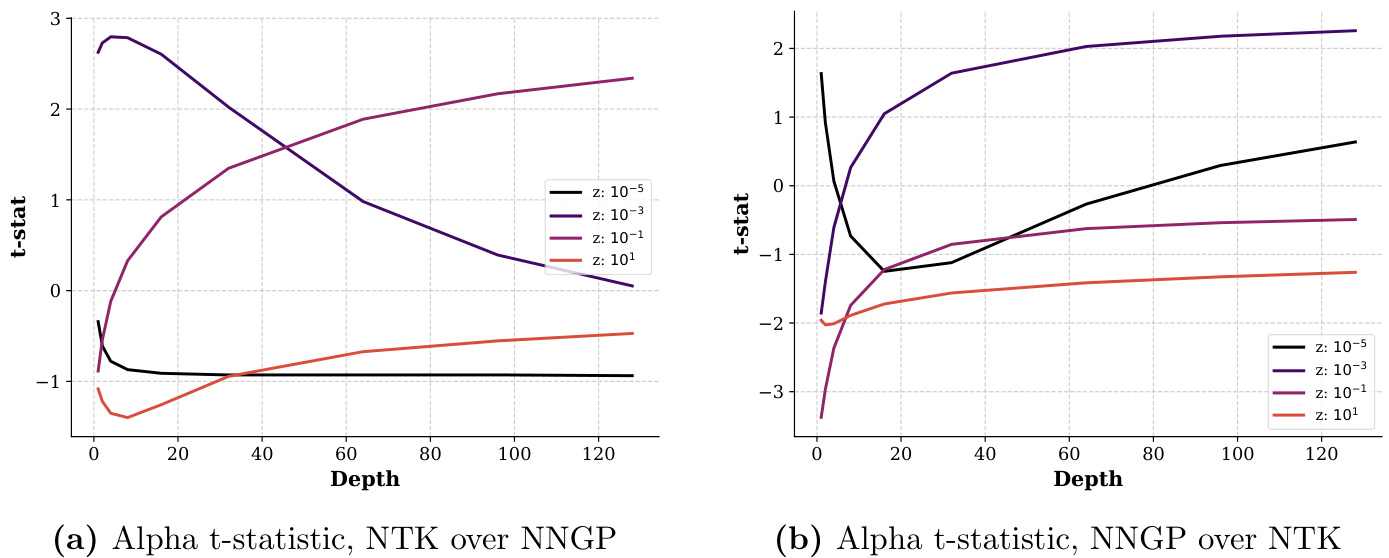
图3(页面42)
- 内容描述:通过NTK核对NNGP核的alpha t统计(a)及NNGP核对NTK核的alpha t统计(b),对比两种核模型的表现互补性。
- 趋势分析:
- 当深度低时,NTK优于NNGP,但深度变大后NTK表现下滑,NNGP表现相对提升。
- 文本联系:诠释了两个核方法优劣互补,特别是浅层时,NTK利用深层细节优势更明显[page::42]。
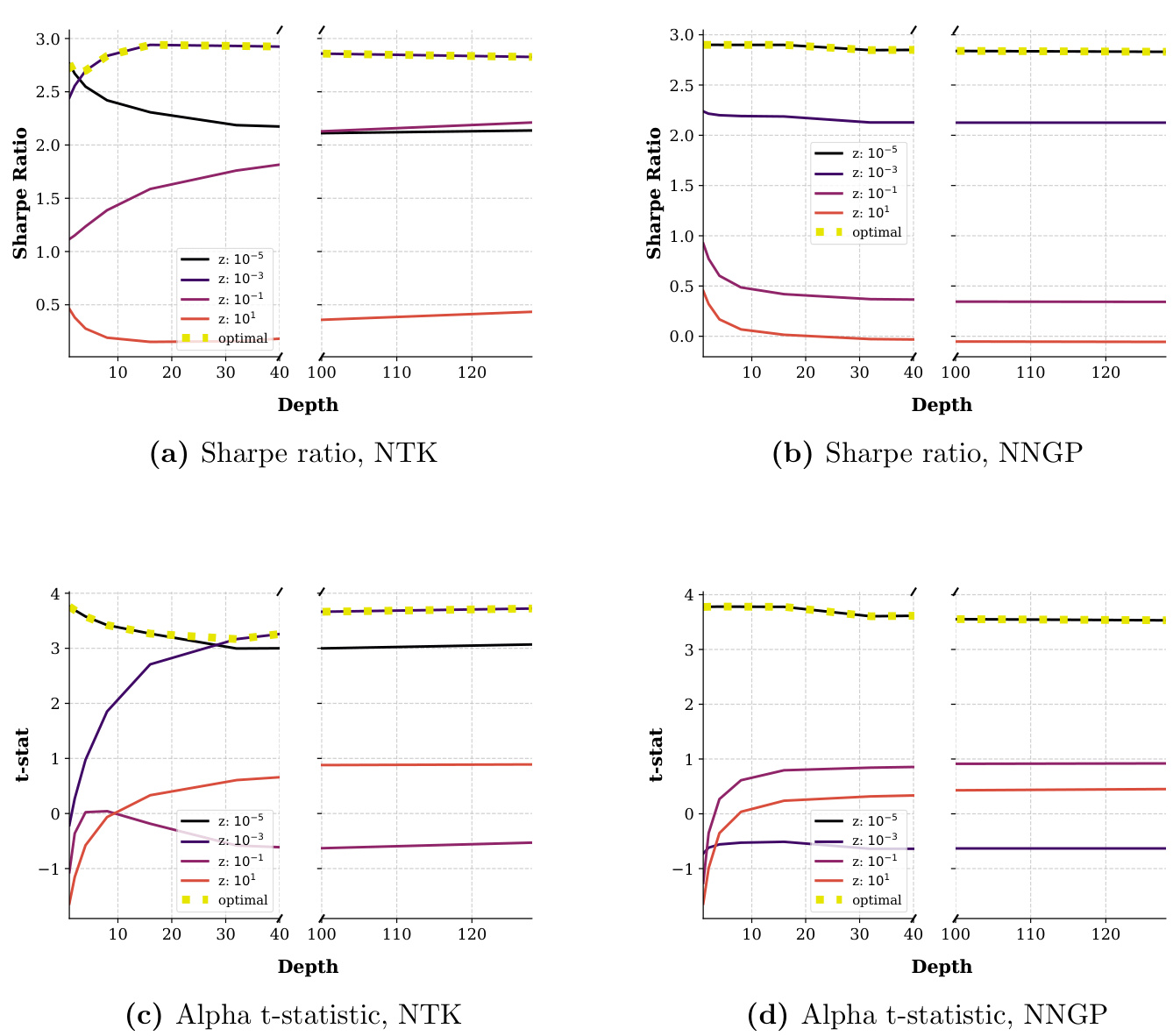
图6(页面45)
- 内容描述:60个月滚动窗口下,ReLU激活函数,NTK和NNGP核的Sharpe和alpha统计随深度变化情况。
- 趋势分析:
- NTK Sharpe比率随深度增长持续提升,饱和于16层左右,极大体现深度复杂度带来的性能提升。
- NTK alpha t先降低后持续上升,表明其捕捉新颖非线性α因子的能力增强。
- NNGP表现提升幅度较小,深度效果不显著。
- 文本联系:佐证足够训练数据下,深度提供更丰富的非线性拟合能力及更优资产定价性能[page::45]。
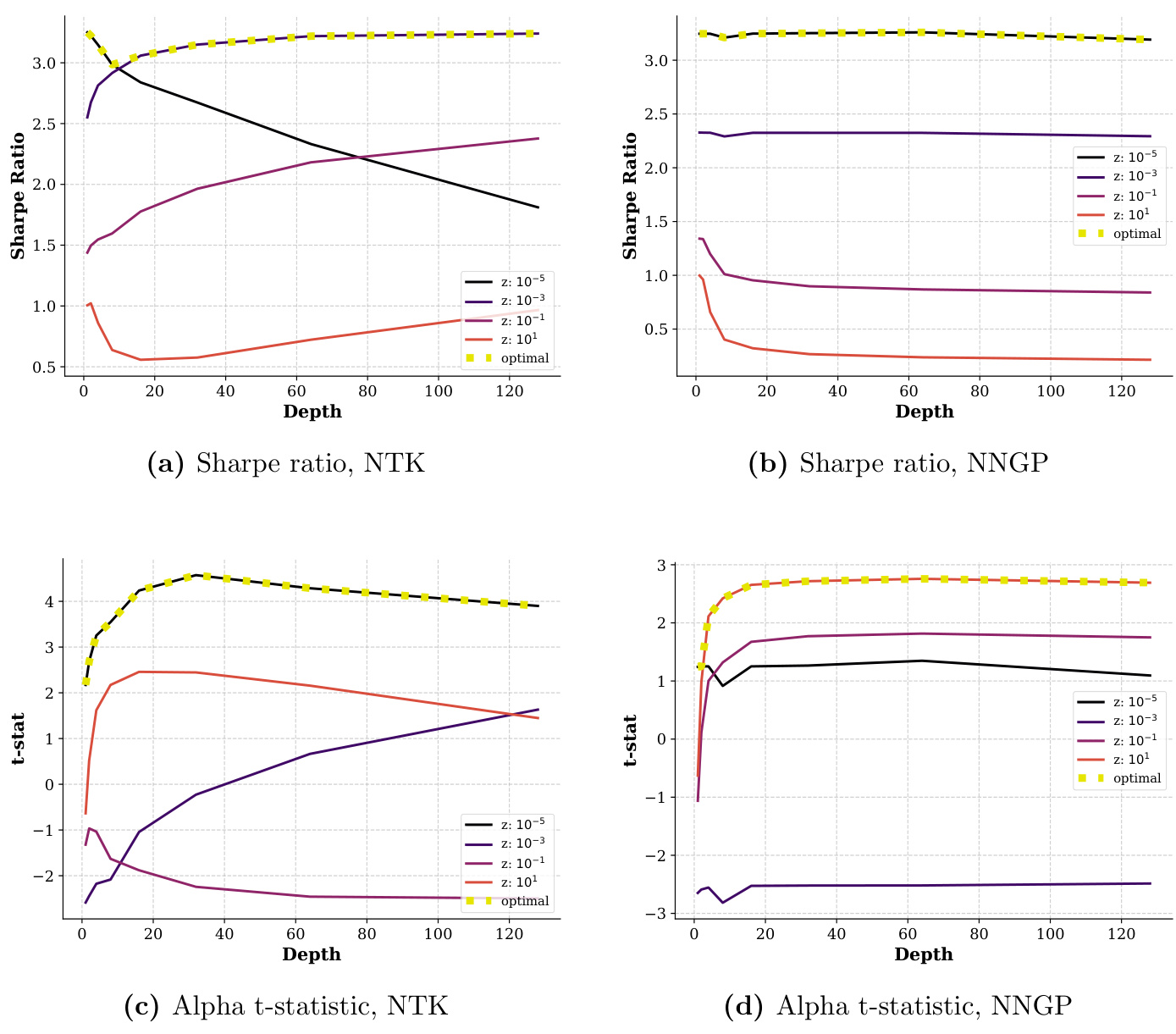
图10(页面49)
- 内容描述:120个月滚动窗口,ReLU激活函数的NTK和NNGP核Sharpe和Alpha表现。
- 趋势分析:
- 浅层和深层网络Sharpe比率接近 (~3.3),但深层模型alpha几乎是浅层的两倍,说明深度能够挖掘标准模型无法捕获的非线性价值。
- 文本联系:强调深度网络提升资产定价模型的信息含量和多样性,而非简单提升夏普比率,深度带来的增益更多体现在捕捉隐性风险因子[page::49]。
---
4. 估值分析
本报告核心在对DNN-SDF理论建模与实证评估,没有传统意义上的估值模型估价部分,而是通过核岭回归框架展现DNN-SDF构造的最优因子组合的估计过程。其“估值”概念隐藏在对SDF构造的夏普率最大化问题求解和正则化路径中,即用梯度下降的光流与神经切线核实现无穷维特征空间下的最优化,体现为:
- 使用岭回归和早停映射到对协方差矩阵的谱收缩;
- 反映在学习率和训练步长的超参数调控上;
- 训练算法作为隐式正则化的特殊形式,是达成高质量估计的关键。
因此,估值分析实质上是大因子模型在无限特征空间中的最优权重正则化处理,敏感性表现为训练超参数的变化[page::22,23,25]。
---
5. 风险因素评估
报告并非重点列举具体传统风险因素,而是从模型视角识别风险:
- 有限样本风险:在样本容量不足时,深度网络易过拟合,表现为深层网络性能下降(如12月窗口实验)。过于复杂的模型可能学习噪音,降低泛化能力[page::28,41]。
- 训练动态不确定性:梯度下降目标非凸,存有大量局部最优解,训练终点受初值和算法参数影响大,可能导致性能不稳定[page::1,2,14,15]。
- 核方法局限:仅在无限宽网络、标准参数化下近似有效,不能描述所有DNN训练范式,限制了模型的表达能力,实际深度学习中“特征学习”机制未被捕捉到[page::30]。
- 随机初始化风险:初始化对最终模型表现有重大影响,错误初始化可能导致性能退化[page::3,26]。
- 过拟合风险:尽管高维模型具有复杂性美德,但若数据不足或正则化不足,则无益反伤[page::4,28]。
缓解策略主要体现在对学习率和训练步长的调节(等价于岭回归正则化),通过调整深度和超参数匹配数据量,以防过拟合和提升泛化[page::2,22]。
---
6. 审慎视角与细微差别
- “无限宽度”与“核极限”的模型局限:本文模型基于NTK核极限,实质捕捉的是宽层DNN但无“特征学习”能力的情形,即DNN行为接近于核回归机。实际深度学习中的特征学习发动机制并未涵盖,限制了理论对真实复杂DNN行为的解释力[page::30]。
- 数据依赖性强:深度优势明显依赖于充裕数据,否则导致模型过拟合,表现反而变差,未必简单的深度增加就带来提升,反映实际金融环境中数据稀缺的限制[page::3,27,28]。
- 不同激活函数影响解释:ReLU与Erf的非线性性质差异带来训练表现的差异,说明模型设计细节对性能有不容忽视的影响[page::26,27]。
- 随机初始化的重要性:初始化标准差等超参数对PTK结构有显著影响,较少文献关注该点,本研究强调了这一细节[page::3,26]。
- 与宽浅网络对比:本文科研重点不同于多数文献只研究浅层NNSDF,研究了极深层配置,拓展了理论视野,但实际是否适用于真实市场环境尚需更多实证[page::4,5]。
- 复杂内在机制尚待揭示:训练算法和数据生成机制的复杂交互对最终模型表现作用巨大,当前仅初探,需等待后续研究[page::2,23]。
---
7. 结论性综合
本报告奠定了深度神经网络在资产定价中的理论基石,首次明确了宽层、极深度DNN训练的SDF等价于大型随机特征因子组合(LFM),且该组合因网络架构和训练算法而异,德彰显深度与复杂性的“美德”,尤其在数据充足环境下,深度DNN能学出更丰富、更复杂的特征,有效改善离样本表现。
- 通过神经切线核(NTK)理论,得到DNN-SDF训练的闭式解析表达式;
- 明确梯度下降和学习率的隐式正则化本质,揭示训练算法对模型泛化至关重要;
- 实证验证随着数据量增加,深度带来明显的Sharpe Ratio和alpha提升,尤其深层网络能挖掘浅层模型无法捕获的非线性因子;
- 不同激活函数表现异质,训练细节(如初始化)对性能影响较大;
- 理论约束了特征学习能力,这也是未来研究前沿,需超越核极限,研究更符合真实深度学习机制的参数化方式。
整体报告系统地缔造了深度学习资产定价领域的理论架构,同时配以严谨实证,推动从浅层、窄层向宽层、超深层的认知变革,奠基了未来深度学习应用于金融风险定价与投资策略设计的方向[page::29,30,41-50]。
---
特别图表引用
部分关键图表如下:
-
-
以上图表直观展示了深度、正则化与数据规模下核方法SDF模型的性能表现,堪称理解本报告实证的关键窗口。
---
金融术语与概念简释
- 随机贴现因子(SDF):衡量资产未来现金流折现回当前价值的关键金融数学工具,与资产收益价格风险关系密切。
- 夏普比率(Sharpe Ratio):收益与波动风险的比值,夏普比率越高表明单位风险下获得的超额收益越多。
- 神经切线核(NTK):无穷宽DNN训练行为可用固定核函数描述,该核表达了参数梯度内积在输入空间的相似性。
- 多层感知机(MLP):基础深度神经网络结构,具有多隐藏层,配合非线性激活函数的全连接网络。
- 特征谱收缩(Spectral Shrinkage):对协方差矩阵特征值进行调节正则化,防止过拟合并提升泛化能力。
- 随机特征模型(Randomfeature Models):利用随机映射非线性变换输入形成高维特征,再线性组合的机器学习方法。
- 因子模型(Factor Model):用一组因子解释资产收益变化的方法,传统定价模型强调因子数量应稀疏。
- 深度复杂性美德(Virtue of Depth Complexity):指网络深度及参数数量增加所带来的模型泛化和性能提升能力。
- 多阶段下降(Multi-Descent):泛化误差随模型复杂度表现为多次下降的现象,扩展自经典的双重下降(Double Descent)现象。
---
以上为本报告的系统解构和丰富解读,涵盖理论推演、数学建模、实证展示及关键图表解析。该研究为金融领域机器学习提供了坚实的数学基础和洞见,指引后续研究如何利用深度结构提升资产定价模型的表达力和实用价值。




