A machine learning workflow to address credit default prediction
创建于 更新于
摘要
本报告提出了一种基于机器学习的信用违约预测工作流程,融合了权重证据(WoE)编码、集成学习策略、多目标遗传算法(NSGA-II)超参数优化及焦点损失函数,有效提升模型在不平衡数据上的预测准确性和金融利润最大化。实证结果显示深度学习模型和集成模型在多个公开数据集上均优于传统统计模型,证明了该方法对金融信贷风险评估的实用价值和可靠性 [page::0][page::1][page::2][page::3][page::4][page::5]
速读内容
- 研究背景与目标 [page::0][page::1]:
- 信用违约预测(CDP)是金融风控关键任务,需分析借款人信息以评估违约风险。
- 提出整合WoE编码预处理、集成模型和多目标超参优化的机器学习工作流程。
- 工作流程设计 [page::2]:
- 预处理阶段采用WoE编码实现异常值剔除、缺失值处理及数据统一尺度化。
- 训练阶段包括统计模型(逻辑回归)、机器学习模型(决策树及随机森林)、深度学习模型(MLP及其集成);
- 使用NSGA-II优化超参数,目标为平衡AUC和最大化预期最大利润(EMP)。

- WoE编码策略及优化 [page::2][page::3]:
- WoE编码通过对类别变量计算默认与非默认概率比值对数,兼顾非线性关系与缺失值处理。
- 集成最优分箱算法确保每箱至少包含5%样本,缺失值单独分箱,保证编码稳定性。
- 超参数优化与模型评估指标 [page::3][page::4]:
- 采用NSGA-II多目标遗传算法以同时优化AUC和金融利润(EMP);
- 分类性能度量包括AUC、F1分数、Brier评分及EMP;
- 引入焦点损失函数缓解类别样本不平衡问题,增强难例学习。
- 实验数据集与性能表现 [page::4][page::5]:
- 使用四个公共数据集:GER(1000样本),HEL(5960样本),HECL(10460样本),PBD(43405样本);
- 深度学习集成模型EMLP在所有数据集均取得最佳AUC和EMP表现。

| Model | AUC | F1 | BS | EMP |
|-------|------|------|-------|-------|
| LR | .800 | .627 | .255 | .051 |
| CT | .701 | .546 | .341 | .041 |
| RF | .792 | .558 | .236 | .037 |
| MLP | .799 | .616 | .273 | .050 |
| EMLP | .801 | .632 | .249 | .053 |
- 多个数据集上的结果一致显示集成深度学习模型优于传统模型,验证方法有效性。
- 结论与展望 [page::5]:
- 提出工作流程有效结合了多种技术,提升信用风险评估的准确性与利润最大化。
- 未来可探索将模型集成入企业系统,支持实际银行信贷决策与企业信用评级。
深度阅读
金融研究报告详尽分析报告
---
一、元数据与概览
- 报告标题: A machine learning workflow to address credit default prediction
- 作者与机构: Rambod Rahman, Marco Parola, Mario G.C.A. Cimino,均来自意大利比萨大学信息工程系
- 发布时间: 无明确日期标注,结合文献引用截止至2023年,估计为2023年左右
- 研究主题: 采用机器学习方法改进信用违约预测(Credit Default Prediction, CDP)
- 关键词: FinTech, 信用评分, 信用违约预测, 机器学习, NSGA-II算法, 权重证据编码(WoE)
报告核心论点与目标
报告针对金融科技领域中信用违约预测任务,提出了一个基于工作流的机器学习方法,强调多步骤协同以充分利用不同机器学习技术的优势。主要贡献包括:
- 使用权重证据编码(WoE)实现数据预处理,统一处理缺失值及异常值,从而兼顾不同模型对数据类型的需求。
- 结合多种机器学习模型,并采用集成学习提高模型鲁棒性。
- 通过利用非支配排序遗传算法II(NSGA-II)进行超参数多目标优化,兼顾预测准确性与金融指标(利润最大化)。
- 引入设计针对数据不平衡的聚焦损失函数(Focal loss)以优化模型在少数类预测上的表现。
总体而言,作者意图构建一个系统且实际可用的工作流工具,为智能化、精准的信用风险评估提供工业和学术的支持。[page::0, page::1]
---
二、逐章深度解读
1. 引言与背景(Section 1)
- 关键论点: 信用评分作为关键金融任务,传统统计模型拟合能力受限于固定假设且难以解决复杂数据关系。深度学习因其优秀的特征表达能力已被广泛关注并证明在多领域具有优势。
- 理论基础: 传统金融服务面临数据量增大与非线性规律挑战,统计模型透明易懂但性能有限,DL和ML方法则具备捕获复杂模式能力。
- 数据预处理重点: WoE编码是一种有针对性的变量编码技术,能有效捕捉特征与目标间非线性关系,处理缺失数据及降维,统一特征尺度,使模型更易训练和泛化。
此章节系统梳理了该领域技术发展现状,为后续多技术融合的工作流设计奠定背景。[page::0]
2. 方法论(Section 2)
2.1 工作流设计
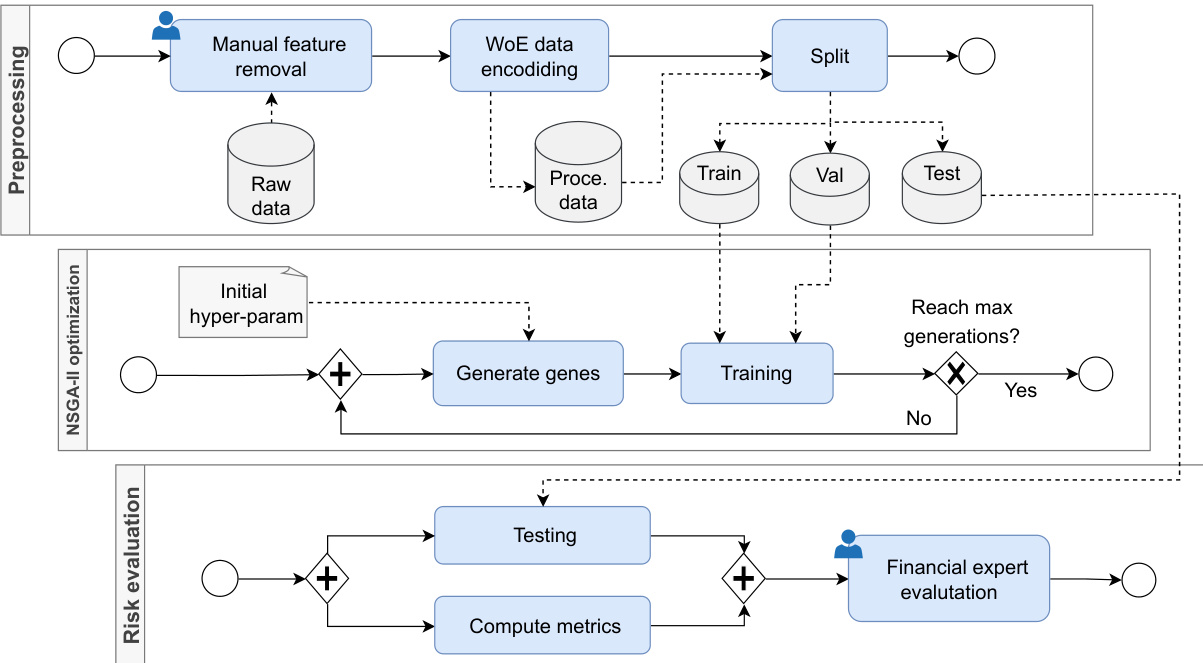
- 步骤概述: 利用BPMN图形化工作流划分为三部分:数据预处理(人工特征筛选、WoE编码)、模型训练及优化(多模型训练、超参数优化)、风险评估(指标计算及金融专家评估)。
- 技术细节: 该阶段把CDP任务定义为基于$n$维特征$x$二分类映射函数$\Psi_{p}$,预测借款人是否违约。重点使用AUC、F1、Brier score等指标评价性能。
- 金融成本考量: 重点强调了不同误判代价(错判好人和违约人的成本差异),设定固定投资回报率ROI作为假定情景,强调了单纯减少误差不等价于最大化利润。
2.2 评估指标创新
- 引入预期最大利润(EMP)指标,综合考虑分类结果的概率和财务回报,优化损失函数及阈值以最大化贷款收益而非仅仅是分类准确率,体现金融场景的实际需求。
2.3 学习模型分类介绍
- 统计模型: 以逻辑回归(LR)为代表,基于sigmoid函数估算类别概率。
- 机器学习: 以分类树(CT)为例,基于递归特征划分,生成决策规则。
- 深度学习: 多层感知机等神经网络模型,具备多层次特征抽取能力。
此处表明作者综合采用多种模型以扩大适用范围及性能优势[page::1, page::2, page::3]
3. 数据编码与超参数优化
- 使用Weight of Evidence (WoE)编码,实现对分类及数值特征的统一编码处理。关键步骤为对数几率比计算,应用最优离散化(Optimal Binning)策略,通过数学规划确保每组符合统计有效性要求(如每组样本数≥5%,缺失值独立分箱等),提升编码质量和预测效果。
- 结合Multi-objective Genetic Algorithm—NSGA-II,同时以AUC和EMP作为优化目标,寻找最佳超参数组合,兼顾分类性能与金融收益。
- 引入聚焦损失函数(Focal Loss),通过调节样本权重,加大对难分类样本(如少数违约者)的关注,提高模型对不平衡数据的鲁棒性。
此设计充分融合数据科学与金融业务需求,突出模型优化的多维考量。[page::2, page::3]
4. 实验设计与结果(Section 3)
- 硬件与软件环境: 采用Python及相关深度学习框架,硬件含AMD 5950x CPU和Nvidia RTX A5000 GPU,保障高效训练。代码和结果开源,支持复现。
- 数据集选取: 采用四个公共且信用评分领域常用的基准数据集,样本数量从1000到43000不等,违约率从4%到52%不等,覆盖多样化场景。
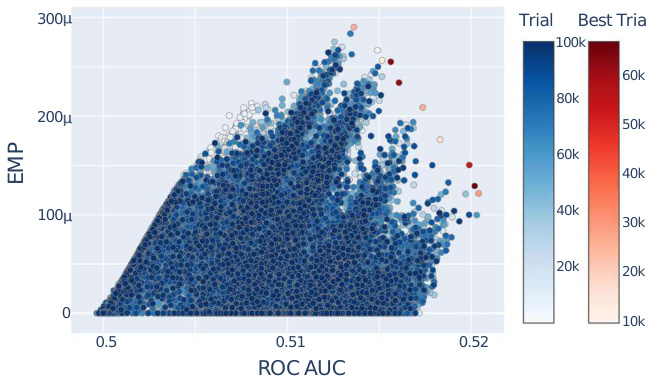
- 超参数优化效果示例: 图2展示随机森林的优化过程及Pareto前沿点,表明多目标折中明显,且算法能有效找到最优权衡解。
- 模型性能对比: 表2-5详细列出不同模型在各数据集上的性能指标(AUC、F1、Brier Score、EMP)。整体趋势:
- 深度学习模型(MLP、EMLP)普遍优于传统统计模型(LR)和单一机器学习模型(CT),证明其在捕获数据复杂性上的优势。
- 集成模型(RF和EMLP)相较基础模型带来性能提升,体现集成技术增强鲁棒性和准确度的价值。
- 不同数据集表现各异,但均展现出上述规律,验证方法的普适性和稳定性。
综合来看,该实验阶段验证了所提工作流的有效性,并展示了基于多目标优化的显著实用价值。[page::4, page::5]
5. 结论与未来展望(Section 4)
- 总结出一个结合WoE预处理、集成多模型、NSGA-II多目标超参数优化的创新工作流,在多个信用评分数据集上均表现稳健且优异。
- 强调该工作流有效提升了信用风险评估的鲁棒性和准确性,为金融机构风险管理提供了实际工具。
- 未来建议将方法集成至企业级软件,提高银行及金融顾问的应用效率,拓宽信用风险评估的实际场景,包括从个人消费者延伸至企业信用评分。
---
三、图表深度解读
图1:机器学习工作流设计(BPMN流程图)
- 描述: 图示清晰展现了三个主要阶段(预处理、NSGA-II优化、风险评估),流程线描绘数据流和控制流,蓝色方框为关键作业单元,人工干预点标记以便决策优化。
- 数据流解读:
- 初始原始数据经人工特征筛选后进入WoE编码模块,输出标准化数据。
- 编码数据分为训练、验证、测试集用于训练管理。
- 利用遗传算法多代迭代超参数搜索,通过“Generate genes”及“Training”循环达到最大代数。
- 最终结果进入测试以及多指标评估,并由金融专家进行业务审视。
- 联系文本论点: 该流程图直观说明了作者声明的分步方法如何系统执行,支持多目标优化和专家反馈机制,体现方法学严谨且可扩展。
- 方法论恰当性: BPMN为业务流程标准,适合表述复杂多步骤机器学习流程,提高流程重用性和透明度。[page::2]
图2:随机森林超参数优化过程散点图
- 描述: X轴为ROC AUC,Y轴为EMP,图中色点代表不同超参数组合,红点标识Pareto前沿最优解决方案。色标区分搜索迭代次数。
- 数据趋势:
- 初始在较低性能指标区域密集分布,随着迭代加深,性能(特别是指标皆提升)呈现向外扩散趋势。
- Pareto前沿上的点显示最佳性能平衡,表明通过多目标遗传算法可以有效寻找最优权衡解。
- 联系文本含义: 直观印证了超参数多目标优化策略的有效性,体现了AUC和利润优化的双目标能力。
- 潜在局限性: AUC值整体偏低(约0.5范围),可能与数据复杂度有关,但整体趋势清晰。[page::4]
表1-5: 各数据集模型性能指标汇总
- 表1: 数据集基本信息,样本量与违约比例差异显著,确保评估结果的泛化性。
- 表2-5:
- 各表均报告AUC(模型的主要性能指标)、F1分数(衡量平衡性能)、Brier分数(概率预测的准确性)、EMP(金融收益指标)。
- 观察各表发现:
- 在同一数据集上,深度学习尤其是集成深度模型(EMLP)在AUC和F1均表现最佳。
- Brier分数较低的模型对应高准确度,说明概率预测更为精确。
- EMP在表现优异模型中最高,强调方法之金融价值导向的成功。
- 对比意义: 各指标的多维呈现兼顾了传统机器学习评估和金融业务需求,强化结论的说服力。
- 数据来源及评价: 公开数据且代码公开,指标计算公开透明,排除数据泄露或过拟合风险较大可能。[page::4, page::5]
---
四、估值分析
本报告未涉及传统意义上的企业估值或市值分析,核心为算法性能与金融指标的多目标优选。其估值核心表现为:
- 指标估值:
- 使用AUC衡量分类准确性。
- 引入EMP作为信贷业务盈利能力的度量。
- 平衡手段: NSGA-II算法通过寻求AUC与EMP的Pareto最优前沿,实质上也是对模型“估值”的多目标折中,选出最佳模型参数集合。
- 敏感性分析: 由超参数搜索过程与Pareto曲线细节体现,通过非支配排序确定最优解,无明显单一极端解,表明稳定性良好。
因此,估值体系体现机器学习模型性能和金融业务收益的交叉衡量,针对金融场景进行了定制化调整。[page::3, page::4]
---
五、风险因素评估
报告虽然未专门设立风险章节,但隐含风险点及其影响可总结如下:
- 数据风险:
- 信用数据常存在缺失和异常,WoE编码选择分箱分别处理缺失,降低数据污染风险。
- 模型风险:
- 不同模型能力差异、数据不平衡可能导致偏差。通过引入聚焦损失函数和集成模型减少单模型风险。
- 业务风险:
- 误分类不同带来的财务损失权重差异显著,EMP指标及复杂阈值策略应对收益风险,但未考虑拒贷机会成本。
- 超参数风险: 优化算法难以完全覆盖参数空间,过拟合风险通过验证集和专家评估阶段缓解。
- 应用风险: 模型在实际业务中的部署复杂度、可解释性与监管合规问题未充分讨论。
整体来看,作者通过多层次技术设计对风险进行了合理控制,但缺乏对业务流程中潜在执行风险的细致阐述。[page::1, page::2, page::3]
---
六、批判性视角与细微差别
- 模型选择偏向深度学习: 报告强调DL优越性,可能低估传统统计模型的解释性与合规优势。
- 指标权衡假设过简: 假设ROI固定且忽视不放贷的机会成本,可能影响EMP的实际有效性。
- 数据多样性限制: 采用的四个数据集虽公开且有代表性,但未包含特殊区域及高风险群体,模型的普适性需进一步验证。
- 缺乏对模型可解释性讨论: 作为信贷风险模型,解释性及透明度尤为关键,但未对这方面展开,可能影响实际应用的合规性。
- 专家评估环节模糊: 金融专家参与评估未明确方法和影响,仅建议存在,缺乏具体指导。
尽管如此,整体分析框架严谨,技术层面创新明显,且符合行业发展趋势。[page::1, page::3, page::4]
---
七、结论性综合
本研究提出并实现了一套系统化的机器学习工作流,针对信用违约预测任务设计,强调了以下关键点:
- 采用WoE编码实现多类型数据的统一预处理,完美处理缺失值,相较传统编码方式更适合金融数据特性。
- 结合统计模型、传统机器学习及深度学习方法,同时利用集成技术增强模型稳定性及预测准确度。
- 引入以预期最大利润(EMP)为核心的金融指标,与传统分类指标(AUC、F1、Brier分数)共同优化,推动模型不仅看重准确率,更关心业务收益。
- 用NSGA-II多目标遗传算法针对超参数进行高效优化,得到性能与利润兼顾的Pareto最优解。
- 聚焦损失函数巧妙应对数据不平衡,避免少数类样本性能损失。
- 实验部分充分利用四个公开高质量数据集,实证验证该方法的优越性,特别是深度学习集成模型(EMLP)在各项指标上均取得领先。
- 工作流设计明确,BPMN流程图表达清晰,为实际工业应用提供了可复制的框架。
尽管存在关于金融业务复杂性和实际部署挑战的细节不足,但整体研究为金融科技领域信用评分模型优化提供了先进且可操作的路径,兼顾技术创新和业务要求。报告的公开开源精神亦促进未来学术界与工业界的持续发展合作。[page::0, page::2, page::4, page::5]
---
参考附录
- 图1: 机器学习工作流设计图
- 图2: 随机森林超参数优化Pareto前沿图
---
以上即对该研究报告的系统深入剖析,涵盖理论、方法、数据、指标、实验及未来方向,力求突出报告技术深度与行业适应性的细节,确保内容完整、专业且适用于金融科技专家及数据科学研究者参考使用。




